


背景
最近,Anthropic 将 Claude Code SDK 更名为了 Claude Agent SDK,以体现他们的愿景:
Claude Agent SDK 并不是只用于编码场景,在 deep research、创作等非编码场景中也同样适用。
官方文档及介绍:
先说几个他们的关键设计原则。
关键设计原则
给 Claude 一台电脑
Claude Code 使用的工具和程序员人群每天使用的工具是一样的,这些工具(如 grep、tail)使它能够:
- 在代码库中找到合适的文件
- 编辑文件
- 代码检查
- 运行 & 调试、编辑
- …
配合 ReAct 模式执行上述操作直到完成任务。
因此,通过让 Claude 访问用户自己的电脑(通过 Terminal),它就拥有程序员写代码所需的一切。
ReAct
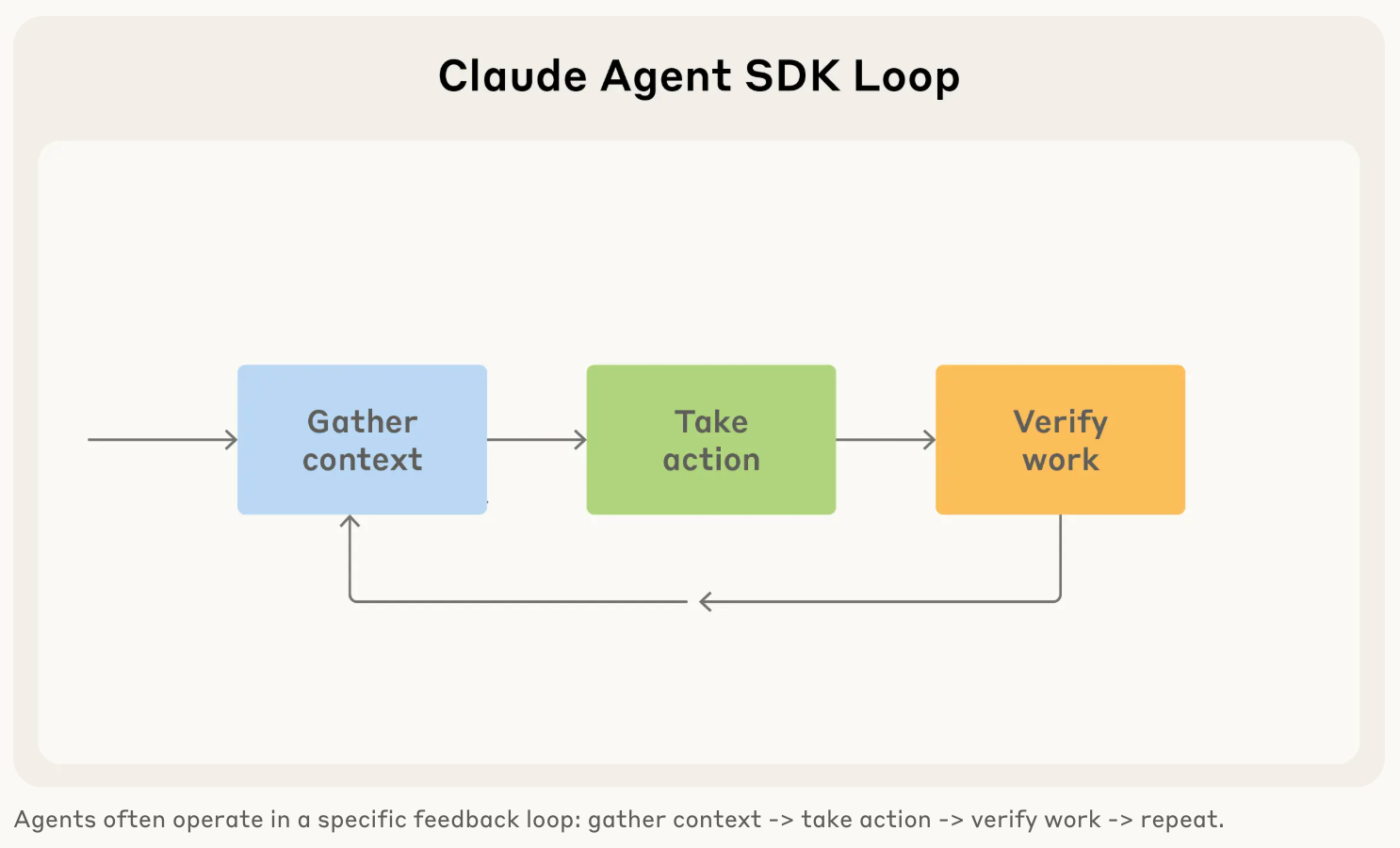
简单的将 ReAct 和 Computer 结合起来就能让 Claude Code 完成大量 “非” 编码型任务,比如:
- 运行 bash 命令
- 编辑与创建文件
- 搜索文件
- 可以读取 CSV
- 搜索网络资源
- 构建可视化大盘
- …
简而言之,变成了通用型 Agent。
管理上下文的能力
上下文不只是指 prompt 写的好不好,这个话题包含了:
- Agentic search 与文件系统组合而成的上下文检索能力,Agent 必须能够自行获取和更新上下文
- 语义检索,虽然比 agentic search 快,但准确性较低、维护成本更高且可调试性差,因此局限性很强,适合需要更快获得结果或更多 variation 时才使用
- Subagents,两个特点:
- 可并行执行,能同时启动多个 Subagents 同时处理不同任务
- 方便上下文管理,Subagents 使用独立的 context window,并且和 lead agent 之间只传递和自身有关的信息,而非完整上下文,这使它们更容易聚焦任务
- 上下文压缩,防止长任务下耗尽上下文
工具与 MCP
不再赘述,基本上都大同小异。
关键能力
Claude Agent SDK 具备的功能,内容并不多。
Streaming Input
所谓的流式输入,指的就是多轮对话的长任务:
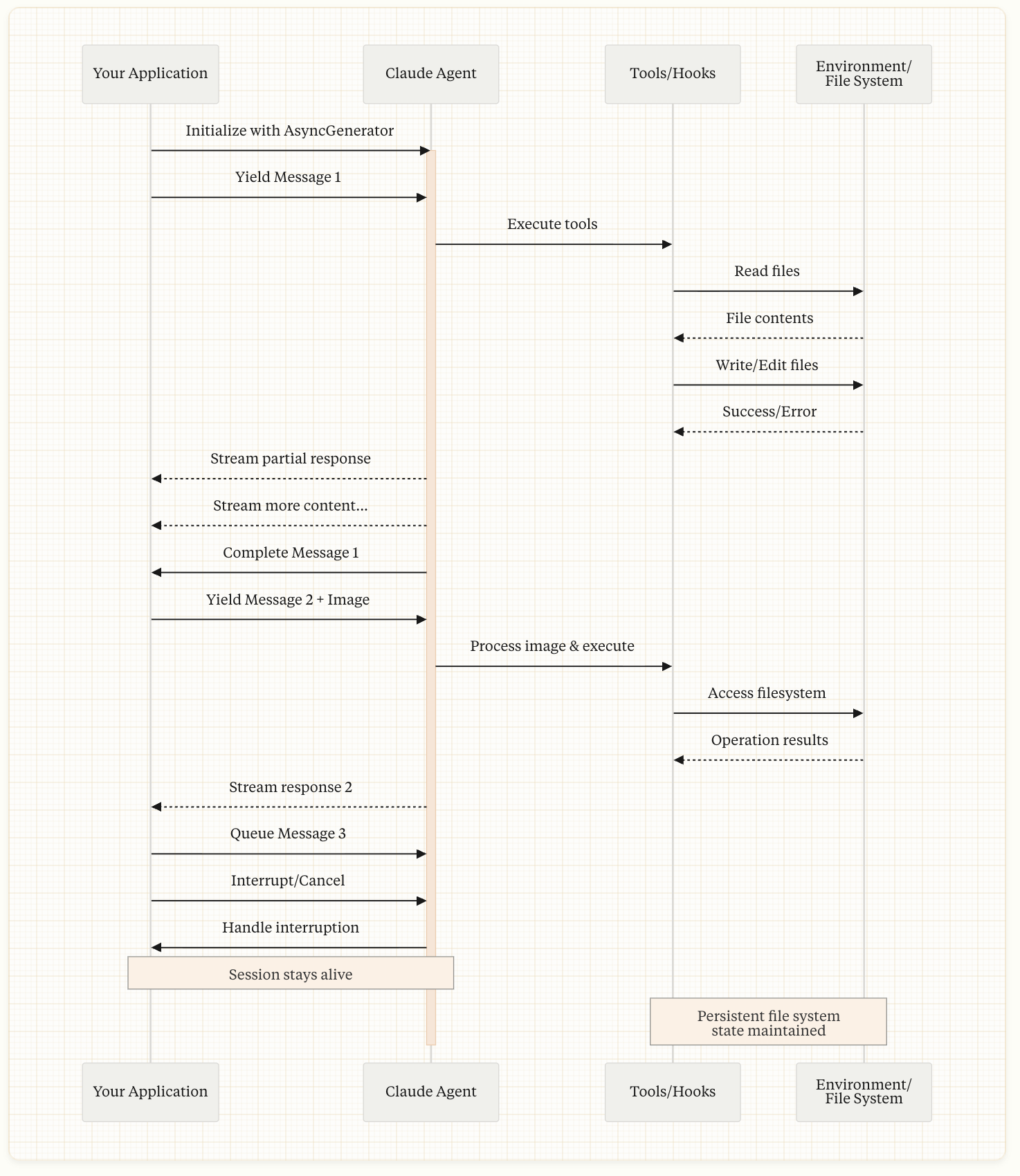
作为对比,简单任务就像一锤子买卖:
- 只需要一次性响应
- 不需要图像附件等
- 无状态环境中运行,例如 lambda 函数
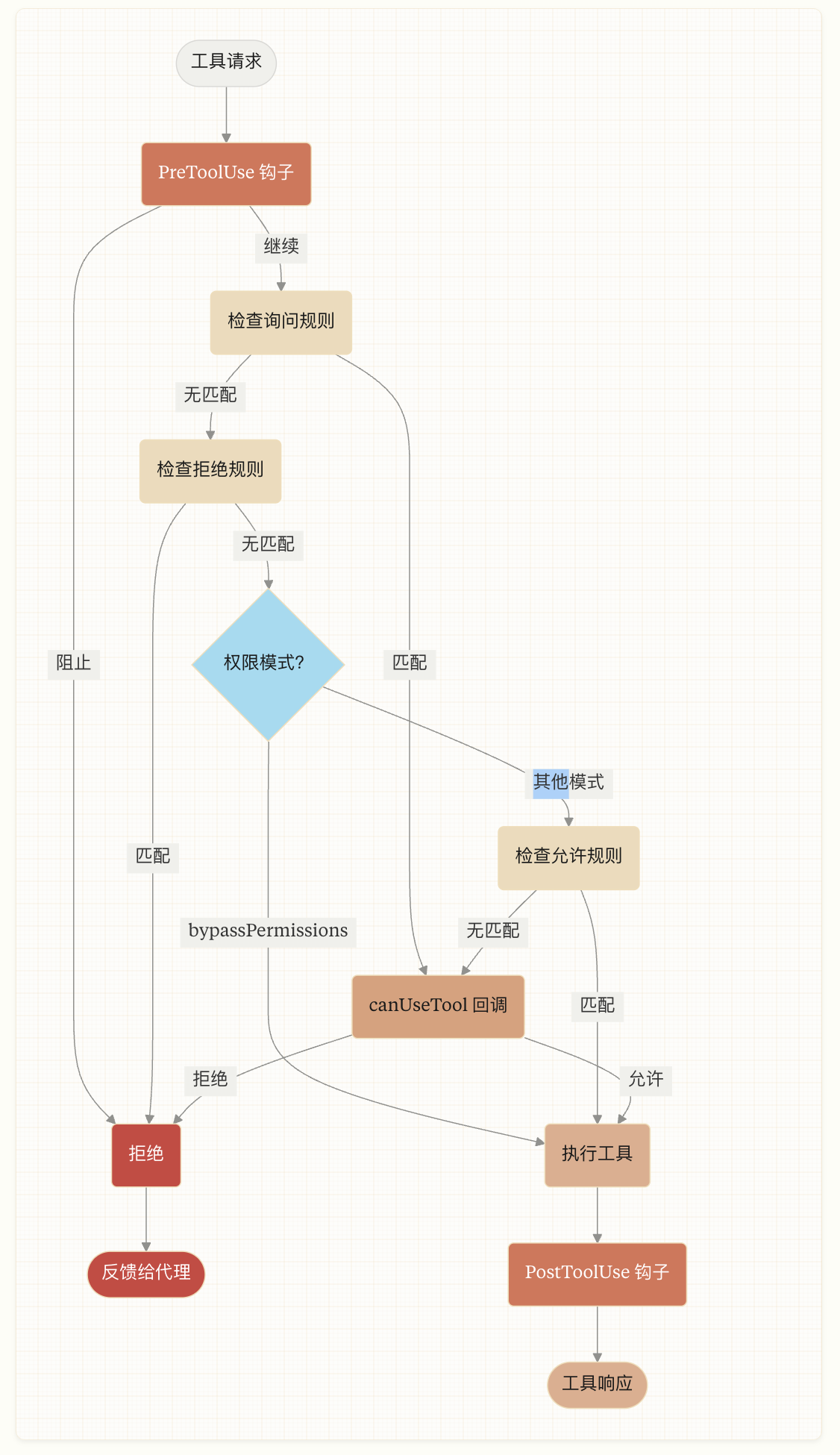
Handling Permissions
控制工具调用:
Session Management
通过会话 ID 管理会话状态,支持会话分叉。
Modifying system prompts
晚点再说。
MCP in the SDK
通过配置自定义 MCP Servers 扩展工具集,示例:
from claude_agent_sdk import query
async for message in query(
prompt="List files in my project",
options={
"mcpServers": {
"filesystem": {
"command": "python",
"args": ["-m", "mcp_server_filesystem"],
"env": {
"ALLOWED_PATHS": "/Users/me/projects"
}
}
},
"allowedTools": ["mcp__filesystem__list_files"]
}
):
if message["type"] == "result" and message["subtype"] == "success":
print(message["result"])
Custom Tools
通过本地代码的形式扩展工具集:
from claude_agent_sdk import tool, create_sdk_mcp_server, ClaudeSDKClient, ClaudeAgentOptions
from typing import Any
import aiohttp
# Define a custom tool using the @tool decorator
@tool("get_weather", "Get current weather for a location", {"location": str, "units": str})
async def get_weather(args: dict[str, Any]) -> dict[str, Any]:
# Call weather API
units = args.get('units', 'celsius')
async with aiohttp.ClientSession() as session:
async with session.get(
f"https://api.weather.com/v1/current?q={args['location']}&units={units}"
) as response:
data = await response.json()
return {
"content": [{
"type": "text",
"text": f"Temperature: {data['temp']}°\nConditions: {data['conditions']}\nHumidity: {data['humidity']}%"
}]
}
# Create an SDK MCP server with the custom tool
custom_server = create_sdk_mcp_server(
name="my-custom-tools",
version="1.0.0",
tools=[get_weather] # Pass the decorated function
)
Subagents in the SDK
一种 Multi-Agents 的实现,定义相当简单:

然后:
const result = query({
prompt: "Optimize the database queries in the API layer",
options: {
agents: {
'performance-optimizer': {
description: 'Use PROACTIVELY when code changes might impact performance. MUST BE USED for optimization tasks.',
prompt: 'You are a performance optimization specialist...',
tools: ['Read', 'Edit', 'Bash', 'Grep'],
model: 'sonnet'
}
}
}
});
Slash Commands in the SDK
能调用 Claude Code 自带的斜杠命令,也能自定义斜杠命令。
调用示例:
import asyncio
from claude_agent_sdk import query
async def main():
# Send a slash command
async for message in query(
prompt="/compact",
options={"max_turns": 1}
):
if message.type == "result":
print("Command executed:", message.result)
asyncio.run(main())
Tracking Costs and Usage
查看对话和工具调用的费用情况,用过 Cluade Code 的话应该不陌生:
Todo Lists
查看和监控待办清单的状态,是 Planning 的一种实现方式。
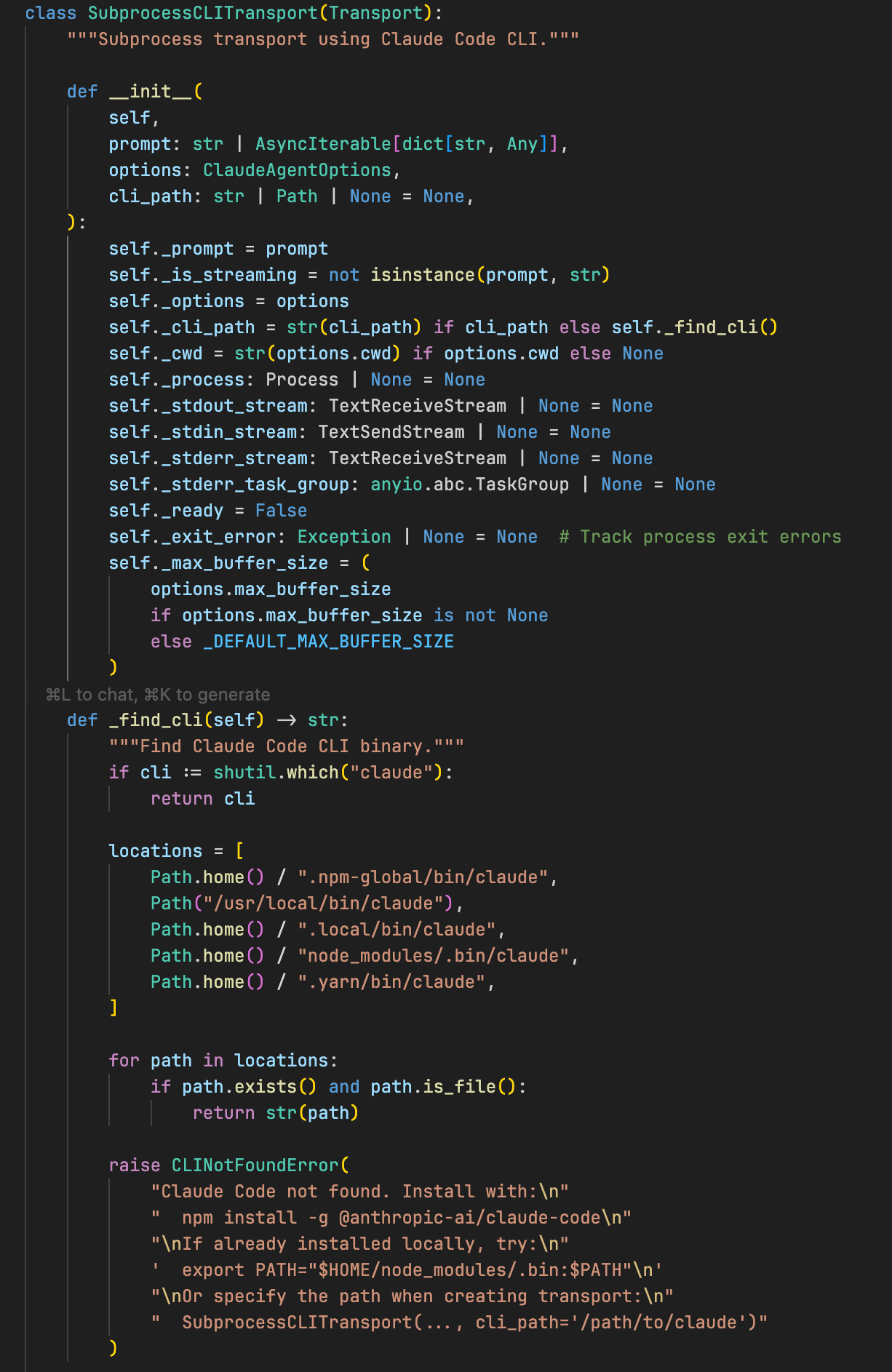
SDK 与 CLI 的关系
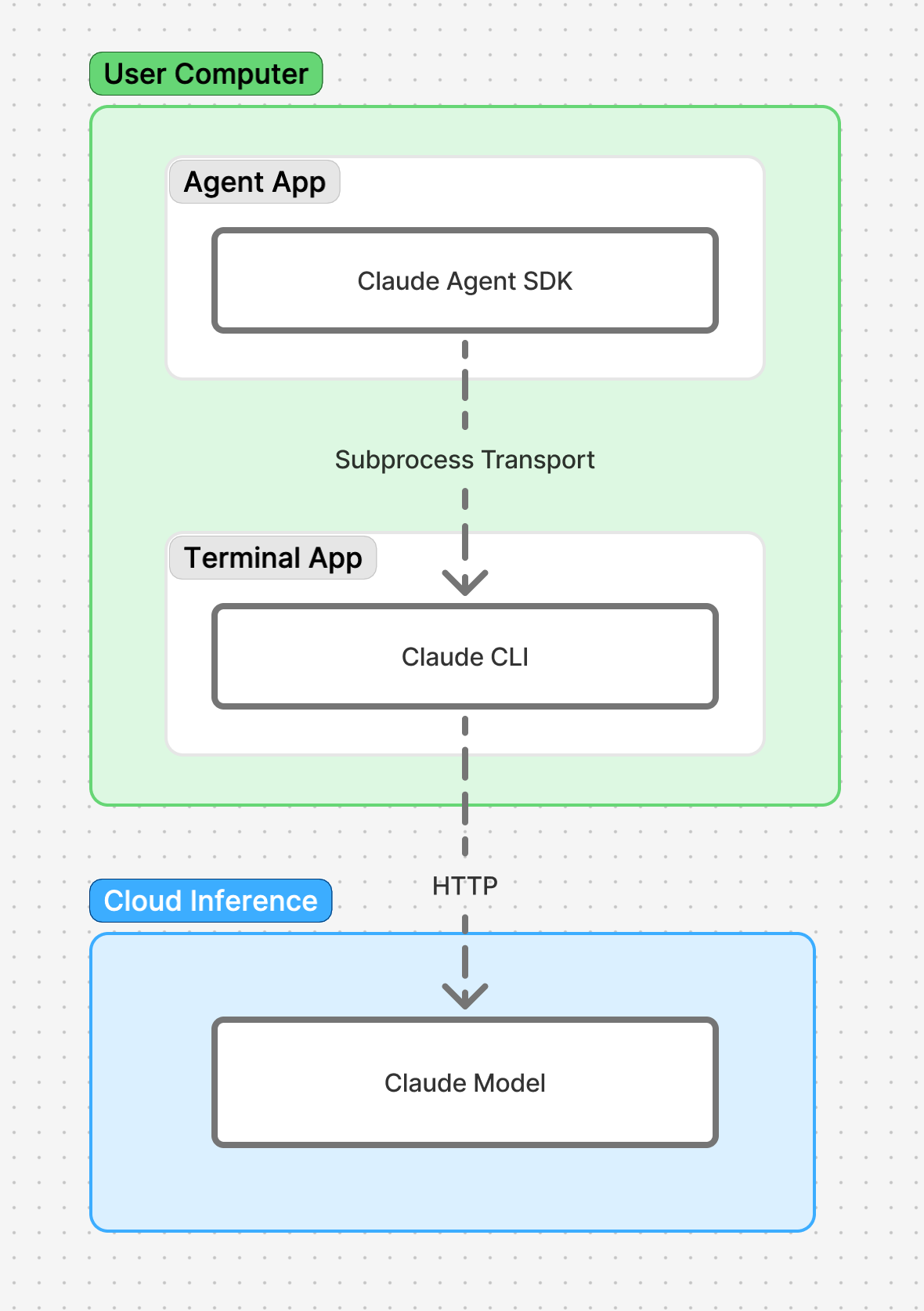
Claude Agent SDK 很薄,它的架构看起来是这样的:
以 interrupt 为例,我们直接通过代码看它的流程。
上层接口:

构建和发送请求:

协议层:
实现层都在 CLI 里,即 Claude Code,再看一眼这张图:
真正干活的是 Claude Code,它以独立进程运行,Claude Agent SDK 就像一个 Client SDK 一样仅封装 CLI 的能力而已。了解这层架构后,你就明白为什么 Claude Agent SDK 里要专门介绍如何 Modifying system prompts,Claude Agent SDK 不能算开发 Agent 的 SDK,只能算调用 CLI 的 SDK,CLI 内部有大量的黑盒实现,比如 CLI 的 system prompts 就自带了这些:
- 可用工具清单及使用说明
- 代码风格和格式指南
- 响应语调和详细程度设置
- 安全和保护指令
- 关于当前工作目录和环境的上下文
因此才需要通过额外的 Modifying system prompts 设计使开发者能够追加或者替换默认的 system prompts。
背后的 Claude Code
有人写了一篇 What makes Claude Code so damn good (and how to recreate that magic in your agent)!? ,正好可以帮助我们了解从 Claude Agent SDK 里看不到的地方。
Claude Code 简称 CC。
CC 的设计充分证明其理解 LLM 擅长和不擅长的地方 — 毕竟是做模型出身的团队。
它的提示词和工具能弥补模型的不足,让模型在擅长的领域发挥优势。
Control Loop 非常简单,易于跟踪和调试。
Keep Things Simple, Dummy
作者提出这是最重要的一点。怎么理解?其实出自工程设计领域著名的 KISS 原则,提炼成一句话:Keep It Simple, Stupid。
LLM 本身就很难调试和评估,任何你引入的额外复杂性(多代理、代理切换、复杂 RAG 检索算法)只会让调试难度提升十倍。如果这样脆弱的系统能正常工作,你也会害怕以后做大改动。所以,Keep Everything in One File~!避免过多的样板代码,然后定期清理重构,干掉技术债,保持简单。
Control Loop
只保留一个主循环,可调试性远胜于复杂的多代理、图节点混合系统:
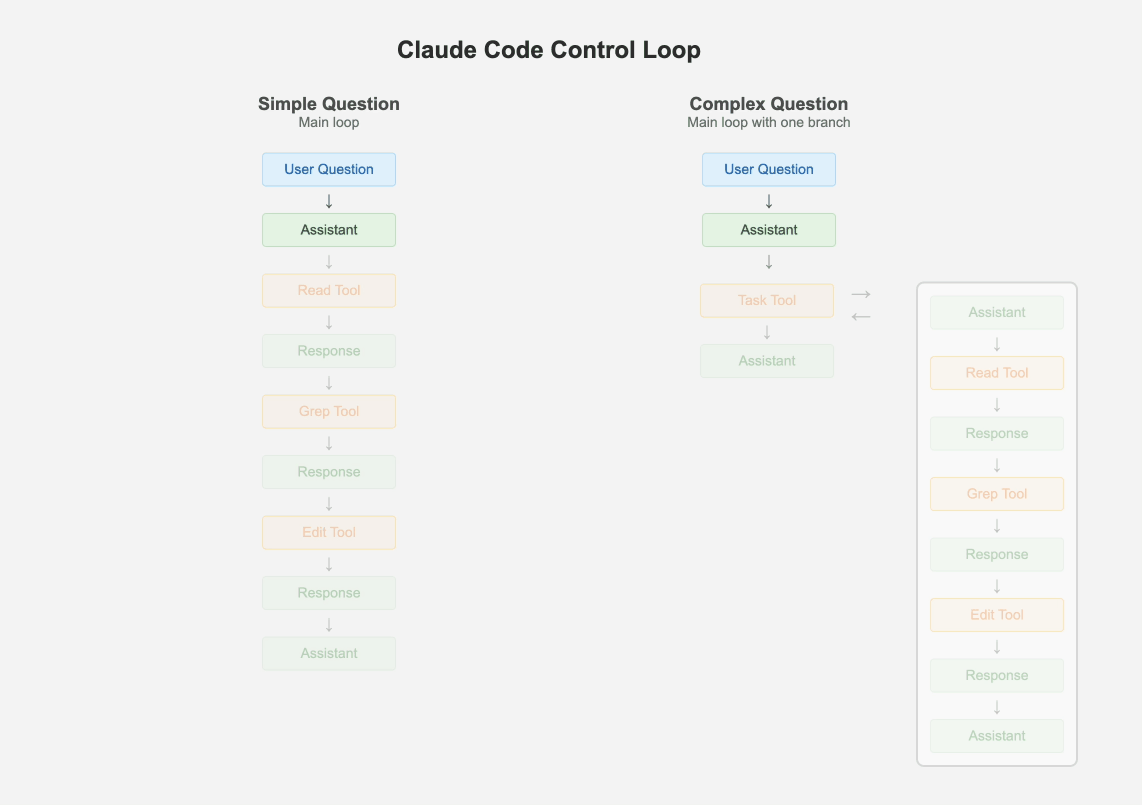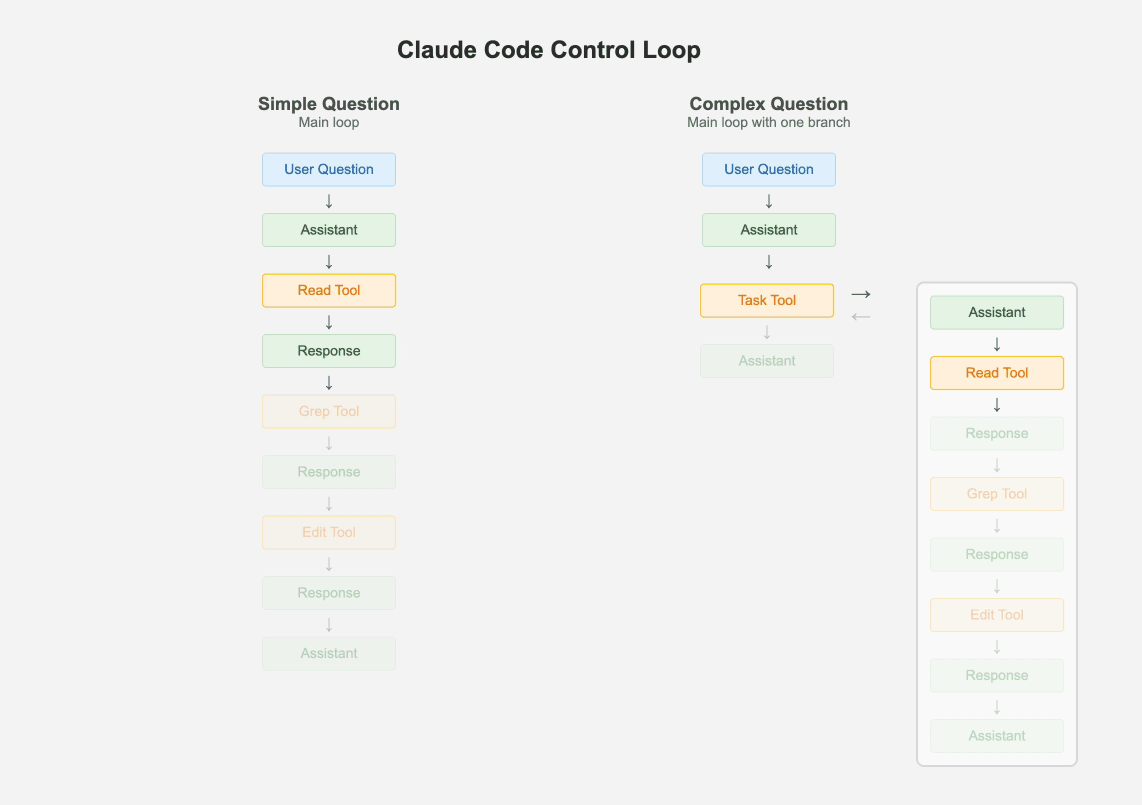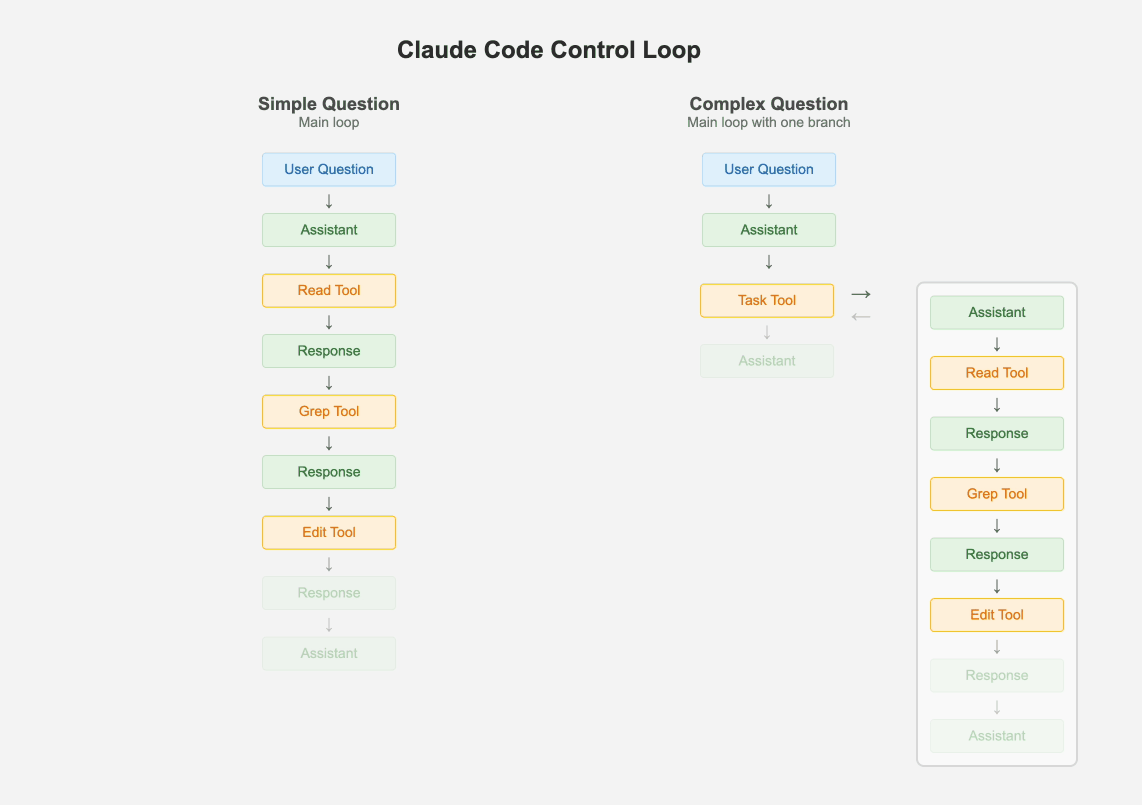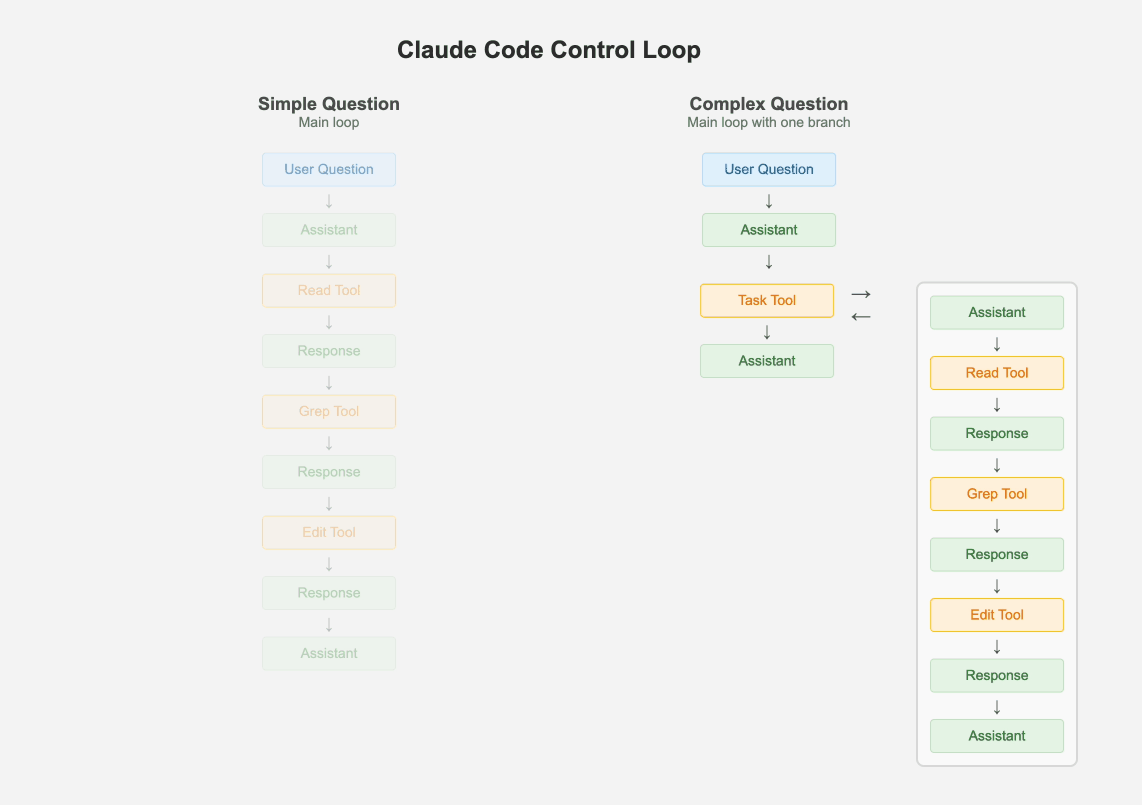
左侧是标准的 ReAct,右侧也是,只是其中一个 Tool 也是属于 ReAct。
此外,CC 超过 50% 的 LLM 调用都用 claude-3-5-haiku,包括读大文件、解析网页、处理 git 历史和总结长对话,甚至「正在处理中……」这种小标签也是用小模型生成处理的,小模型比标准模型(Sonnet 4、GPT-4.1)便宜 70-80%。
Prompts
CC 的提示词非常详细,可谓量大管饱,这一点与 Cursor 非常不同,CC 由于本身是 LLM 基座提供商 Anthropic 的产品,在消耗 tokens 这件事上并没有那么畏手畏脚。
光 System Prompt 约 2800 tokens,Tools 则高达 9400 tokens,然后 User Prompt 通常总是包含 claude.md 文件,又有 1000-2000 tokens。SP 涵盖了语气、风格、主动性、任务管理、工具使用策略和任务执行,还包含日期、当前工作目录、平台和操作系统信息以及最近的提交记录 — 增强模型的上下文感知能力。
claude.md 对理解用户偏好至关重要。大多数 Code Agent 都支持规则文件(如 Cursor Rules / claude.md / agent.md),有无规则文件表现差异巨大。LLM 默认每一个新的 session 都没有以往的记忆,例如可以强制 LLM 跳过某些文件夹或使用特定库,为了确保长期记忆和个性化,这些文件必不可少,CC 每次用户请求都发送完整的 claude.md 内容。
https://minusx.ai/blog/decoding-claude-code/ 文末有完整的 Prompts 记录。
XML 标签 + Markdown:结构化提示
模型对结构化输入通常更敏感。CC 把这一点发挥到极致:大量使用 XML 标签与 Markdown 结构化提示。
其中一些有代表性的:
<system-reminder>,常放在段落末尾,提醒模型那些「容易被遗忘的小事」,看似啰嗦,实际效果很好:
<system-reminder>
这是一个提醒:你的待办事项列表当前为空。不要向用户明确提及这一点,因为他们已经知道。如果你处理的任务会受益于待办清单,请使用 TodoWrite 工具创建一个;如果不需要,就忽略这条提醒。再次强调,不要把这条提醒直接说给用户听。
</system-reminder>
<good-example>/<bad-example>,当存在多条看似合理的路径时,正反示例比抽象描述更有 “路感”。比如引导如何使用绝对路径避免频繁(cd:尽量通过绝对路径保持当前工作目录,只有在用户明确要求时才使用 cd):
<good-example>
pytest /foo/bar/tests
</good-example>
<bad-example>
cd /foo/bar && pytest tests
</bad-example>
此外,用清晰的 Markdown 标题(如 # Tone and style、# Tool use policy)把 SP 分区,能让模型更容易抓住重点,并按设计执行。
Tools:让 LLM 像人一样操作工具,而不依靠 RAG
LLM 检索优于 RAG 检索
Cursor 在 Context Engineering 的第一个关键突破就是使用 RAG 将项目整个 codebase 进行索引,并通过语义(向量)搜索的方式给 LLM 提供整个项目的上下文,而 CC 选择了一套和 Cursor 完全不同的检索代码上下文的方案,那就是基于 Unix 工具的检索方案,例如使用 grep、find、git、cat 等等终端命令而不是 RAG 的方案。
RAG 一派认为 grep 方案的召回率低,检索出大量不相关的内容,不仅费 token,并且效率慢,因为 LLM 需要不断对话和不断检索新的上下文。
grep 一派则认为复杂的编程任务需要精准的上下文,而 RAG 的方案在代码检索的精度上,表现的并不佳,毕竟代码的语义相似度不等于代码关联的上下文,更不等于业务上下文。
这种争议随着 Cursor 引入 grep 方案后慢慢减少了,并不能说 CC 的选择绝对正确,但毫无疑问这个选择能大幅减少 Agent 的复杂度,贴合 CC 的设计理念。
如何设计好工具?(高/中/低层工具全都要)
CC 有低级(Bash、Read、Write)、中级(Edit、Grep、Glob)和高级工具(Task、WebFetch、exit_plan_mode)之说。
CC 能用 bash,为什么还要单独的 grep?关键在于工具使用频率和准确性。CC 用 grep 和 glob 很频繁,所以单独做成工具,但特殊场景下也能写通用 bash 命令,有点类似 Agent 用 code 解决问题的能力。
使用频率 x 成功率的权衡。
让 Agent 自己维护 To-Do List
长时间运行的 Agent 有一个常见的问题是 “上下文腐烂”,一开始很积极,后来逐渐偏离目标。通常解决方案有:
- 显式待办(一个模型生成待办,另一个模型执行)
- 多代理交接+验证(产品/项目经理 Agent -> 实现 Agent -> QA Agent)
CC 尽量避免多 Agent 交互,它给了一个 TodoWrite 工具,让模型自己维护 To-Do List,这样做的好处是:
- 专注:Prompt 里会反复强调,要经常参考 To-Do List,这让模型始终记得最终目标是什么
- 灵活:在执行中,它能借助「交错思考」动态增删或拒绝任务,自己修正路线
- 透明:用户能清楚看到当前计划与进度,信任更足
这种做法兼顾了「明确计划」和「动态执行」,确保长流程里不容易跑偏。
ps:ToDoWrite 是 CC 里使用率排名第三的工具。
指令遵从:简单,但有效
把语气/风格讲清楚
和 CC 对话 “很有品味”,原因之一是其 SP 里包含了专门的语气、风格和主动性部分,以及大量指令和示例,比如:
- 「重要:除非用户要求,不要用不必要的开场或收尾」
- 「如果不能或不愿提供帮助,请避免解释动机或后果,免得显得说教」
- 「只有在用户明确要求时才使用表情符号」
这些看起来吹毛求疵和智能无关的规定,塑造了它简洁、直接、克制的沟通风格,让人感觉在与一个高效的同事合作。
THIS IS IMPORTANT:这很有用
让 LLM 不要做某件事时,最有效的方式之一依旧是明确且强烈的强调——大写、加粗、反复强调,比如:
- 「重要:除非被要求,不要添加任何注释」
- 「非常重要:避免使用 find/grep 等命令进行搜索,请改用 Grep、Glob 或 Task。避免 cat/head 读取文件,请使用 Read」
- 「重要:绝不要为用户生成或猜测 URL」
又简单又有用 — 而且可能是最有用的方法之一。
用算法展示规则
SP 通常包含大篇幅的做与不做,当 tokens 数量过多时容易让 LLM 感到困惑,CC 的解决方案是在 SP 里除了说以外,还用了流程图、算法告诉 LLM 一步一步怎么做,如下:
# Doing tasks
The user will primarily request you perform software engineering tasks. This includes solving bugs, adding new functionality, refactoring code, explaining code, and more. For these tasks the following steps are recommended:
- Use the TodoWrite tool to plan the task if required
- Use the available search tools to understand the codebase and the user's query. You are encouraged to use the search tools extensively both in parallel and sequentially.
- Implement the solution using all tools available to you
- Verify the solution if possible with tests. NEVER assume specific test framework or test script. Check the README or search codebase to determine the testing approach.
- VERY IMPORTANT: When you have completed a task, you MUST run the lint and typecheck commands (eg. npm run lint, npm run typecheck, ruff, etc.) with Bash if they were provided to you to ensure your code is correct. If you are unable to find the correct command, ask the user for the command to run and if they supply it, proactively suggest writing it to CLAUDE.md so that you will know to run it next time.
NEVER commit changes unless the user explicitly asks you to. It is VERY IMPORTANT to only commit when explicitly asked, otherwise the user will feel that you are being too proactive.
- Tool results and user messages may include <system-reminder> tags. <system-reminder> tags contain useful information and reminders. They are NOT part of the user's provided input or the tool result.
在关键的 Task Management、Doing tasks 和 Tool Usage Policy 等部分,都详细写出了算法流程,也有大量启发式和场景示例。这些流程化算法化的指令,比零散的 Do/Don’t 更容易被执行,能让 LLM 的行为更加结构化、可预测,也更不容易出错。
Anthropic 的启示
打造强大的 Agent,不一定要复杂的框架和繁琐的工程化。其实,简单的 Agent 一样可以很强大。
Claude Code 没有追求花哨的新技术,而是选择相信模型,把复杂的部分交给模型处理,让系统专注于基础和调度。与其堆叠工具和流程,不如把复杂留给模型,把简单留给系统,或许效果更好。
Anthropic 很有野心,他们正试图把 Claude Code 变成一个高渗透、广适用的通用智能入口,就像当年的 Chrome,只要开发者用 Agent,背后就有 Claude Code 的身影,最终进入每个用户的日常环境、成为每台电脑的标配。