

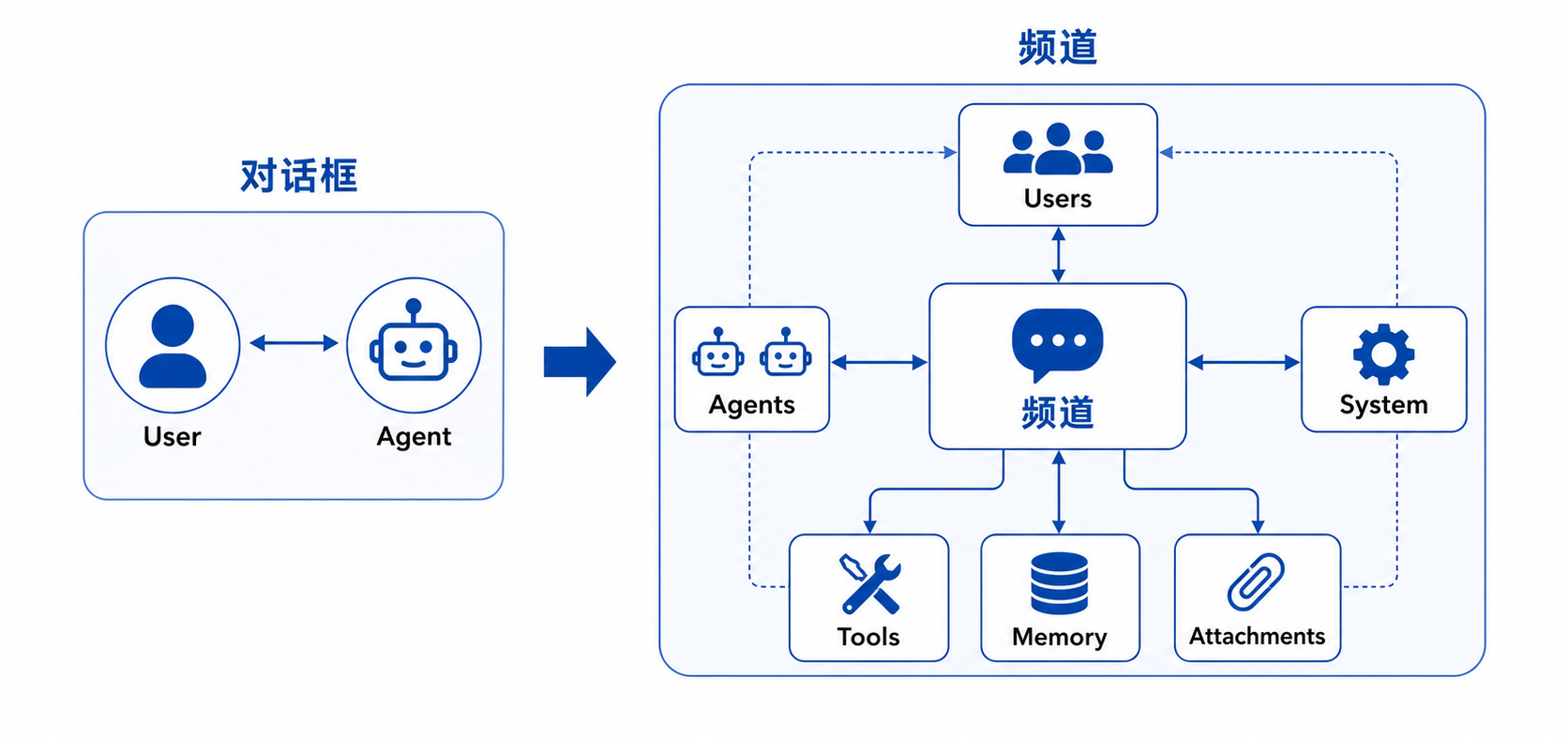
背景
过去很长一段时间,AI Agent 产品的默认形态都是一个对话框:用户输入一句话,Agent 回复一段内容;用户继续追问,Agent 继续响应。
这种形态很自然,因为 LLM 最早就是从 Chat Completion 发展出来的,产品界面也就顺着 “人和模型对话” 的方式往前走。但如果把 Agent 放进真实工作流,对话框很快就会遇到瓶颈。
这篇文章的灵感,来自我最近对 Slock 这款产品的观察,以及它创始人在播客里谈到的一个判断:要让对话内容既对人类友好,又对 Agent 友好,这件事本身是需要精心设计的。我们在这里借 Slock 聊聊这种产品背后的工程问题。
Slock 本质上是一种 agent-human 协作方式,它不是先从 “频道 UI” 出发,而是先回答一个问题:当人、Agent、系统事件和工具结果需要围绕同一个任务持续协作时,应该如何组织对话、身份、投递、上下文和状态?
频道只是这种协作方式最容易被人理解的产品隐喻,它让人知道自己是在一个共享工作空间里协作,而不是在和某个孤立的 ChatBot 来回问答,真正重要的不是消息长得像群聊,而是系统把人和 Agent 放进了同一个可持续推进任务的协作结构里。
更关键的是,这件事不会自然发生,一个频道如果只按人类聊天习惯来做,Agent 看到的往往只是一段松散、含糊、噪声很大的文本;如果只按机器可读协议来做,人类又会觉得笨重、不自然、难以协作,让同一段对话同时适合人和 Agent 确实挺难的。
Agent-human 协作方式要解决什么问题
真实工作通常不是一个人把需求一次性说清楚,然后等另一个人独立完成;它往往是一个 长时、多角色、异步的协作过程:
- 多个用户在同一个空间里补充信息
- 多个角色负责不同任务
- 消息 & 协作是异步的
- 中间会有附件、链接、工具结果和系统事件
- 任务可能持续数小时甚至数天
- 历史记录既是上下文,也是任务状态和协作线索
所以人机协同的 Agent Channel 不应该被理解成 “群聊版 Chatbot”,它真正要解决的问题是如何设计一种 agent-human 协作方式:让 Agent 能进入真实工作空间,和用户、系统、工具一起持续推进任务完成。协作上的挑战:
- 从对话框到频道,难点不是只有 UI,而是要同时设计人类界面和 Agent 可消费的工程协议
- 对话框里的核心对象很少:用户消息、Agent 回复、上下文历史。频道里的对象要复杂得多
至少需要处理这些东西:
- 用户、Agent、系统都能成为频道参与者
- 消息可以被展示、引用、搜索,也可以触发某个 Agent 工作
- Agent 可以读频道、写频道、拉人、被 @ 唤醒、处理附件、访问 memory
- 工具调用结果需要回到频道,但不能污染正常交流
- 频道状态要可恢复、可追踪、可解释
频道消息也不只是聊天记录,它同时承担了几种职责:
- 沟通记录:人和 Agent 在这里协作
- 任务上下文:Agent 需要从历史消息里理解当前目标
- 执行证据:工具做了什么、结果是什么,要能被回看
- 来源线索:关键行为是谁触发、代表谁发出,要能解释
- 恢复入口:中断后,Agent 要能从频道状态继续推进任务
一旦进入频道场景,身份、投递、上下文和权限都会变成一等公民。
同时对人和 Agent 友好
听 Slock 创始人的访谈 时,里面有一个很有意思的说法:产品需要同时考虑 UI/UX 和 AI/AX。换句话说,一个面向 Agent 的产品不能只对人类友好,也要对 Agent 友好。它不是把 Agent 塞进一个聊天窗口,而是把对话本身设计成同时服务人和模型的协作介质。
这个判断放在 Agent Channel 上尤其重要,因为 “对人友好” 和 “对 Agent 友好” 不是同一个优化目标,也不能指望靠一个更大的模型自动解决。人类喜欢的是低认知负担、自然表达、可视化状态、少一点协议感;但 transformer 架构的模型消费的是 token 序列,它更需要稳定、显式、可压缩、可检索的结构。对人类来说,一个头像加昵称就足够理解 “谁在说话”;对 Agent 来说,如果没有稳定的 sender_id、消息来源、时间、引用关系和权限信息,这条消息就是一段含糊的文本。
所以产品上要同时维护两层界面:
- Human UX:让人能自然地发消息、@ 同事、拖入附件、看到进展
- Agent UX:让模型能可靠地读取主体、意图、状态、约束、工具结果和上下文边界
这就是需要设计的地方:产品层要决定哪些信息应该被人感知,这不是要求用户界面长得像 JSON or TUI;协议层要决定哪些信息必须被机器稳定读取,系统层要保证两者指向同一个事实。否则 UI 里看起来顺畅的协作,到了 Agent 侧可能只是不可验证的文本片段;Agent 侧看似完整的状态,到了用户侧也可能变成无法理解的黑箱。
比如一条消息在 UI 里可以显示成:
小张:@设计助手 帮我把这份 brief 整理成三版海报方向。
进入 Agent 上下文后,要把消息整理成 agent-facing message:人类可读的 display label 仍然保留,但身份、mention、回复目标和附件权限都用稳定字段表达:
[target=#all msg=msg_abc123 time=2026-05-26T12:16:20+08:00 sender=user:123456] 小张: <@agent:a> 帮我把这份 brief 整理成三版海报方向
[attachment id=file_456 name=brief.pdf mime=application/pdf access=read]
Agent 需要这些结构化线索来稳定工作。
身份系统:从展示身份到可验证身份
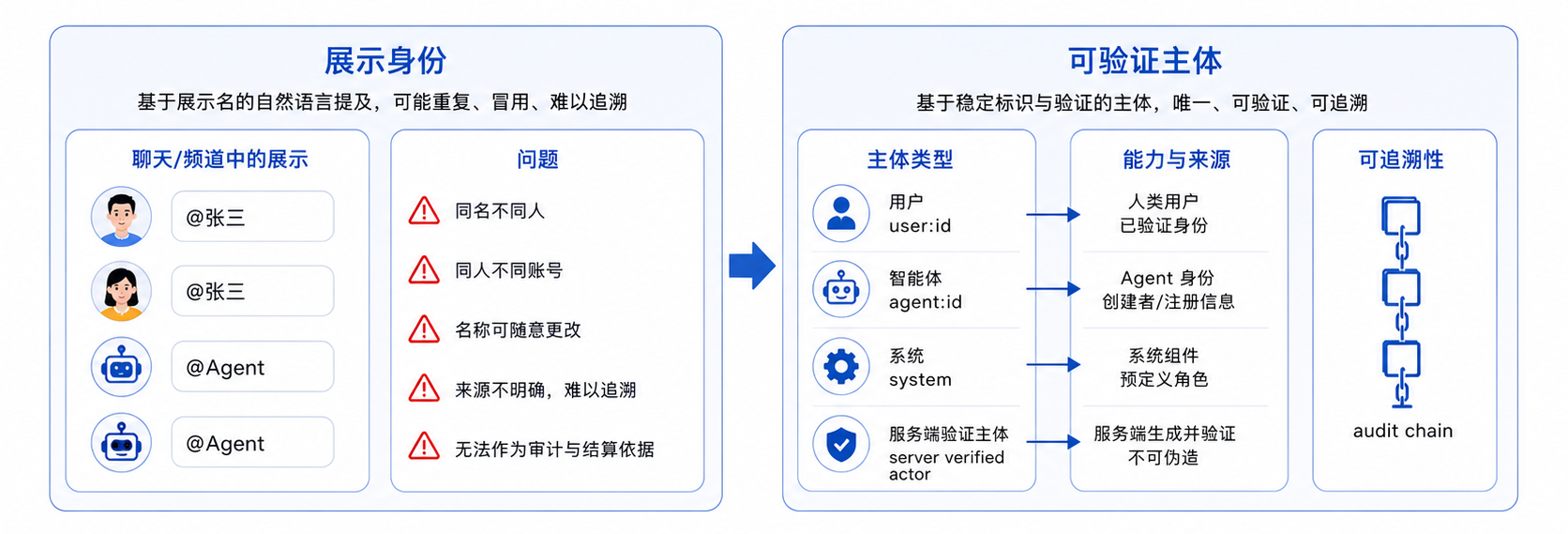
频道协作里第一个容易低估的问题是身份。
在普通聊天产品里,很多身份信息是为人类展示服务的,比如昵称、头像、备注名、自然语言里的 @张三。但这些东西并不适合作为系统协议的基础:
- 昵称会变
- 昵称会重复
- 头像不能证明身份
- 文本里的
@张三可能只是普通文本 - Agent 名称也可能冲突
- 消息可能来自用户、Agent、系统或工具结果
如果频道里只有人类,这些问题通常还可以通过上下文和社交常识解决;但 Agent 不应该依赖这种模糊判断。Agent 需要的是稳定、可解析、可验证的主体。
这里可以借 passkeys 做一个类比。
很多人理解 passkeys 时,会把它简化成 “不用密码,用设备证明你是你”。这个理解方向是对的,但如果更严谨地看 WebAuthn 的认证过程,它并不是服务端拿公钥加密一段 challenge 再让客户端解密,而是服务端发出 challenge,认证器用私钥对相关数据签名,服务端用已登记的公钥验证签名。也就是说,系统相信的不是用户输入了什么可复制的秘密,而是用户是否控制了对应的私钥。
这对 Agent Channel 的启发是:身份不能建立在可复制、可输入、可伪造的文本上。
<@user:123>、<@agent:456> 这类 typed mention 很有用,但它本身只是一个可解析地址,不是身份凭证。它解决的是 “这段文本指向哪个稳定对象”,不是 “这条消息真的由这个对象发出”。
真正可信的身份,应该来自服务端确认过的主体和来源:
| 层次 | 示例 | 作用 | 不能替代什么 |
|---|---|---|---|
| 展示身份 | 昵称、头像、@张三 | 给人看 | 不能做身份和权限依据 |
| 可解析地址 | <@user:123>、<@agent:456> | 消除 mention 歧义 | 不能证明消息来源 |
| 可验证主体 | sender_id、登录态、Agent 注册信息 | 确认谁在发起行为 | 不能自动获得所有权限 |
| 行为授权 | role、capability、delivery、tool permission | 决定能做什么 | 不能替代来源记录 |
因此,Agent Channel 的消息协议里至少要区分几个概念:
display_name:展示用,可以变化sender_id:稳定主体,不能靠模型生成sender_type:user、agent、systemmentions:结构化解析后的被提及对象permissions:当前主体在频道里的能力边界audit:围绕 Agent 身份记录行为来源、时间和触发链路
这里说的 audit,不是把频道历史当成主要的合规材料来做,而是为 Agent 身份服务。只要频道里允许 Agent 发言、代表用户执行动作、回填工具结果,系统就必须能回答:这条消息来自哪个已注册 Agent?它是自主执行,还是用户授意?触发它的是哪次 delivery?它使用了哪些权限?没有这条身份和行为来源链路,Agent 看起来就只是一个会说话的昵称,责任归属和权限边界都会变得含糊。
一个典型错误是把 @Agent 当成真实投递依据。在 demo 里可能工作正常,但只要出现重名 Agent、改名、复制粘贴消息、跨频道引用,就会出问题。更稳的做法是:UI 展示 @Agent,消息协议里保存 <@agent:agent_123>,服务端再根据频道成员、权限和 delivery 规则决定是否唤醒对应 Agent。
同样,Agent 发言也不能只有 “assistant message”。至少要能区分:
- Agent 自主执行后的回复
- 用户明确授意 Agent 发送的消息
- 系统投递给 Agent 的任务
- 工具执行结果的可见回填
- 系统生成的状态事件
否则后续讨论责任归属和权限边界时,会非常混乱。
消息投递:频道不是简单广播
对话框里,用户发一条消息,Agent 回复一条消息,这个模型很简单。但频道里,消息的可见性和投递应该拆开。
消息是写入频道的事实,投递是交给某个 Agent 处理的任务。 这两者不能混为一谈,因为频道里一条消息可能有不同含义:
- 普通聊天:只用于展示,不触发 Agent
- @ 某个 Agent:需要生成明确 delivery
- @ 多个 Agent:可能生成多个 delivery
- Agent @ 另一个 Agent:可能触发新的协作链
- 系统事件:需要进入历史,但不一定需要模型阅读
如果把频道消息简单广播给所有 Agent,会带来几个问题:
第一,成本不可控。每个 Agent 都读同一段历史,都尝试判断自己要不要响应,频道越活跃,消耗越大。
第二,行为不可控。没有明确 delivery 时,Agent 很容易出现抢答、重复答、误响应。尤其是多个 Agent 都具备相似能力时,谁应该处理当前任务需要由系统协议决定,而不是靠模型自觉。
第三,来源不清楚。用户到底是让某个 Agent 做事,还是在和人聊天?某个 Agent 为什么被唤醒?另一个 Agent 为什么没有参与?如果系统没有 delivery 记录,事后很难解释。
因此,一个相对清晰的频道模型是:
- UI 负责把用户输入、附件和 mention 提交给 Channel Service
- Channel Service 校验身份、权限和频道成员关系
- 服务端解析 typed mention,生成结构化
mentions - 根据 mention、订阅规则或系统策略生成 delivery
- Agent Service 消费自己的 delivery
- Agent 通过频道工具读取上下文、发送消息、写入结果
- 所有行为回到 Channel Service 记录状态变更和来源链路
这里的关键是:Agent 不是频道的后台超管,而是频道里的参与者。它可以通过工具参与协作,但不能绕过频道协议直接写数据库,它能看到什么、能回复什么、能调用什么工具,都应该由频道服务和权限系统控制。
上下文:频道历史不能直接塞进 prompt
频道场景里的另一个难点是上下文。
单人对话里,上下文通常就是最近几轮消息,加上一些系统 prompt 和 function calling 结果。但频道里的 context 要复杂得多:
- 当前频道有哪些成员
- 哪些 Agent 被 @ 了
- 哪些消息是投递给当前 Agent 的
- 哪些附件和当前任务有关
- 哪些 memory 是属于频道的长期记忆
- 哪些系统事件只是状态记录,不需要进入推理
- 当前任务是否有未完成状态
如果把频道历史完整塞进 prompt,很快会遇到三个问题:
第一是 context window。频道是长期存在的,消息会不断累积。哪怕模型支持 1M context 也不可能把所有历史都当成有效上下文。
第二是噪声问题。多人频道里大量消息并不服务于当前任务,比如确认、闲聊、状态通知、系统事件、重复附件。把它们全部塞进去,会降低模型判断质量。
第三是结构问题。频道里的重要信息往往不是自然语言本身,而是结构化关系:谁 @ 了谁、哪个附件属于哪个任务、哪个工具结果对应哪个 delivery、哪条消息是对哪条消息的回复。
频道场景更适合分层处理上下文:
- 最近消息:保留原文,保证 Agent 理解当前交流
- 相关历史:按 mention、thread、任务、附件、关键词检索
- 结构化状态:participants、delivery、memory、tool result 单独进入上下文
- 历史摘要:只用于背景,不作为事实来源的唯一依据
- 按需恢复:当模型需要完整消息或附件时,通过工具展开
Agent Channel 的上下文工程不是 “把消息列表截短”,而是把频道里的协作状态变成可检索、可压缩、可恢复的结构。
边界:Agent 是频道参与者,不是后台超管
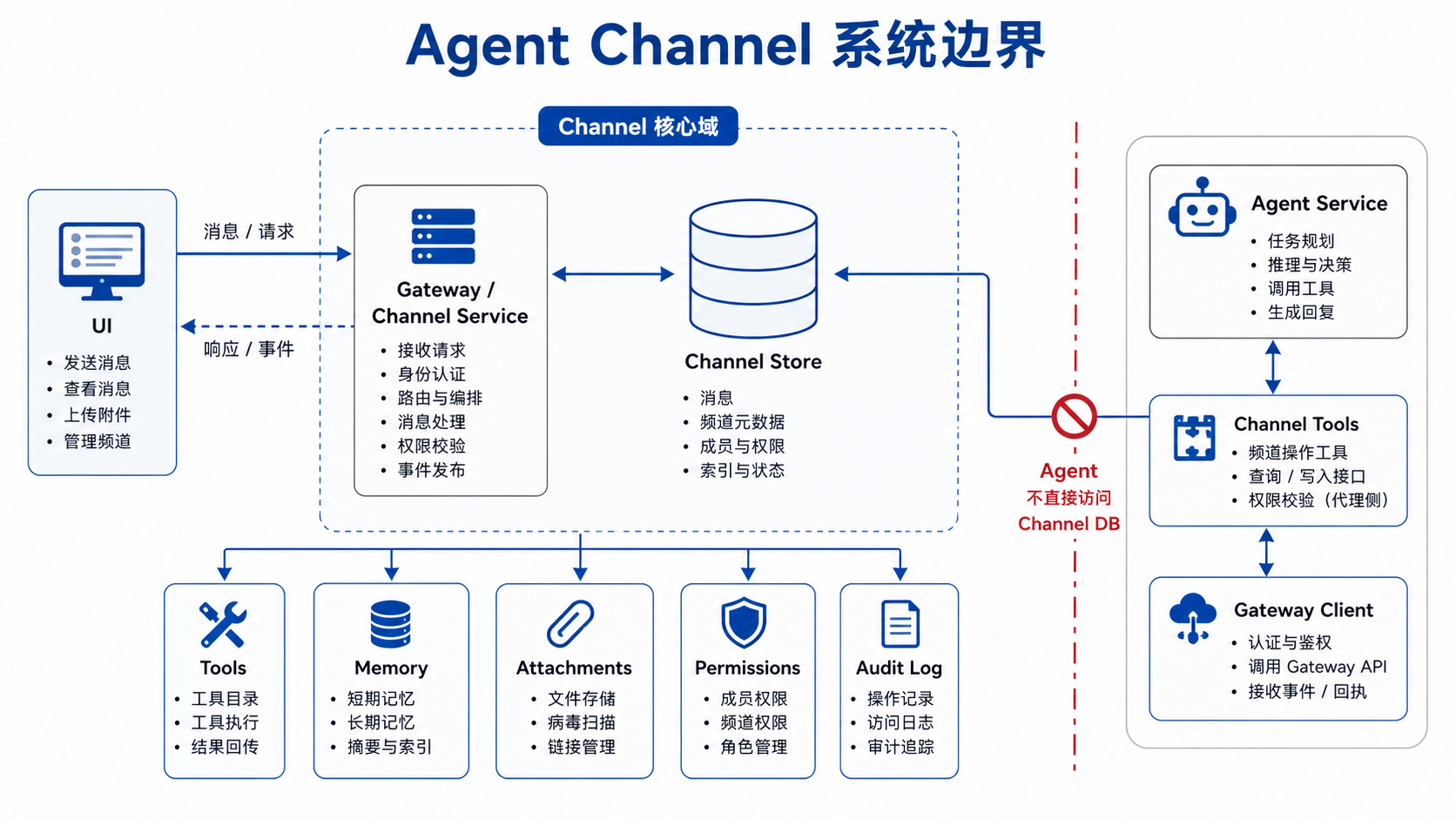
一种直觉做法是让 Agent 直接拥有频道数据库的读写能力,这样实现快,调试也方便,但问题很大:Agent 可以绕过权限、绕过可见性、绕过身份来源记录,甚至写出用户界面无法解释的状态。
更合理的边界是:Channel Service 管频道状态,Agent Service 只通过工具或 client 使用频道能力。
这些工具可以包括:
read_channel_messages:读取当前 Agent 可见的消息search_channel_messages:按关键词、时间、参与者搜索历史send_channel_message:以受控方式发送频道消息read_attachment:读取当前任务允许访问的附件read_memory/write_memory:访问频道或参与者相关记忆
工具层要负责几件事:
- 权限校验:当前 Agent 是否能读这个频道、看这个附件、发送这类消息
- 可见性控制:哪些工具结果公开,哪些只回给 Agent
- 错误表达:权限不足、资源不存在、状态冲突,要变成 Agent 可理解的反馈
- 来源记录:谁以什么身份通过什么工具做了什么,结果是什么
- 幂等与恢复:重复调用时不会产生不可解释的副作用
这和普通工具调用的区别在于,频道工具不是单纯的能力扩展,而是协作协议的一部分。
比如发送消息不是一个简单的 post(text),它至少涉及:
- 发送者是谁
- 是否代表用户
- 是否包含 mention
- 是否触发新的 delivery
- 附件引用是否合法
- 消息是否公开可见
- 是否需要写入身份和来源记录
如果这些逻辑散落在 Agent prompt 里,系统会非常脆弱,它们应该由服务端协议承接,Agent 只通过明确的工具接口表达意图。
如何测试 Agent Channel
Agent Channel 做到这里,单轮 prompt eval 就不够了。
单轮评测通常只能回答一个问题:模型对某个输入能不能给出看起来合理的输出。但频道型 Agent 要回答的问题是:
- 是否正确理解了用户在频道里的真实意图
- 是否只响应了应该响应的消息
- 是否正确处理了 mention 和投递
- 是否能从附件、memory 和历史消息中恢复上下文
- 是否在工具失败后做了合理恢复
- 是否真的完成了跨系统任务
- 是否留下了可复盘的关键过程
这也是 SaaS-Bench 给我的一个启发。
SaaS-Bench 不是让 Agent 回答一道题,而是让 Agent 在真实 self-hosted SaaS 环境里完成长链路工作流,然后用 verify.py 检查应用最终状态。它的任务也不是随机生成的,而是从职业角色和 workflow seed 出发,经过 LLM Builder 生成、专家 Challenger / Refiner 多轮把关、静态检查和人工执行验证,最终保留下可运行、可验证的任务。论文 里还区分了两个指标:
- Resolved Score:所有 checkpoint 通过才算任务完成
- Checkpoint Score:按权重统计部分 checkpoint 完成情况
这两个指标很适合解释 Agent 产品里的一个常见现象:Agent 看起来做了很多,也可能完成了不少中间步骤,但端到端任务仍然失败。
不过,对 Agent Channel 来说,SaaS-Bench 还少了一层:用户本身也应该被模拟。SaaS-Bench 的用户主要是静态任务描述,而真实频道里的用户会追问、补充信息、打断、改需求、上传附件、对中间结果表示不满意。要测频道型 Agent,仅有 verifier 还不够,还需要有足够强的 User Agent:
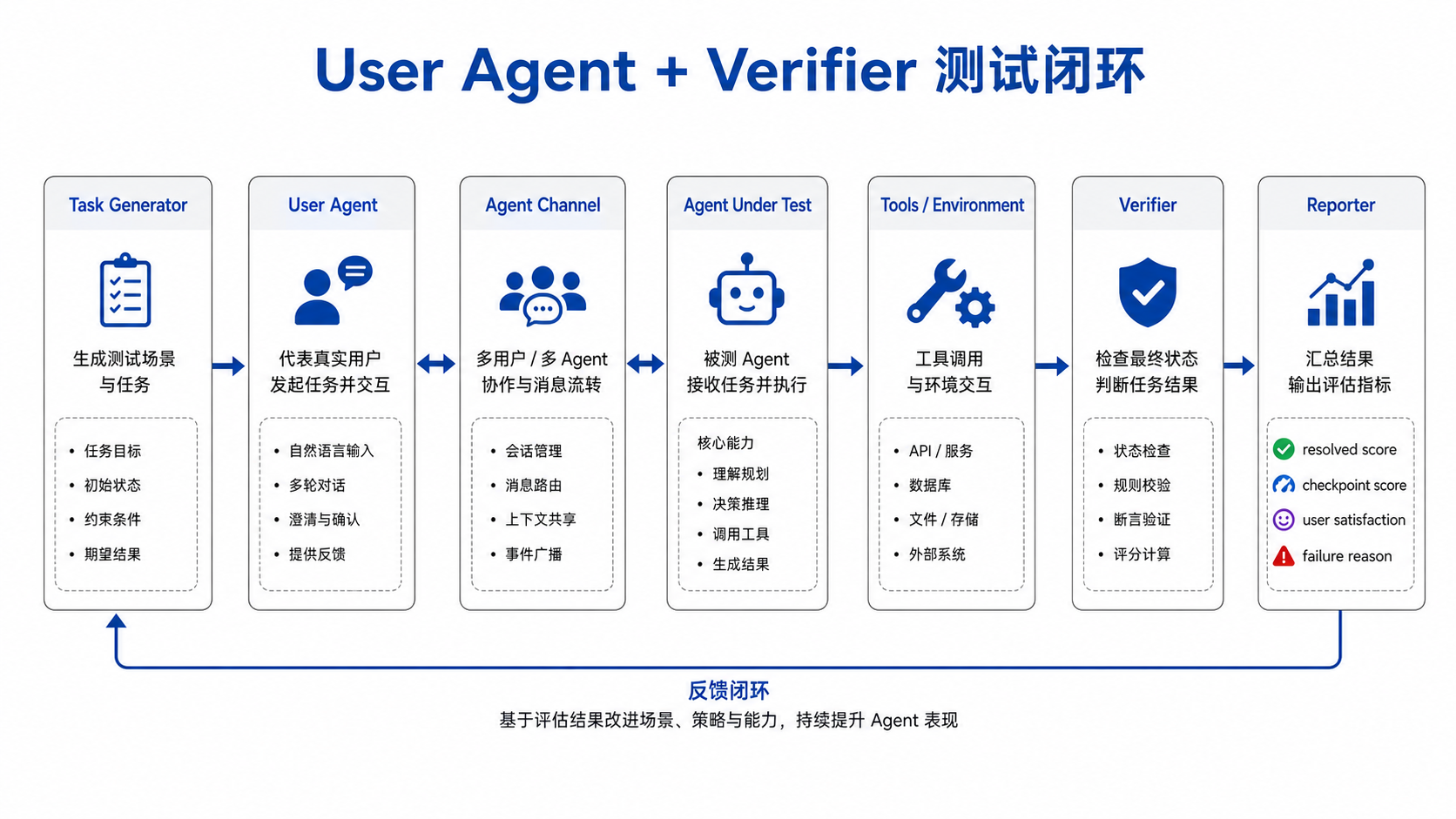
一个更贴近产品的测试闭环可以是:
- Task Generator 生成任务、角色、约束、初始状态和附件
- User Agent 代表真实用户在频道里发起任务
- Agent Under Test 在频道里接收投递、读取上下文、调用工具
- User Agent 根据中间结果继续追问、纠错或变更需求
- Verifier 检查最终系统状态和关键中间状态
- Reporter 输出 resolved score、checkpoint score、user satisfaction 和 failure reason
这里 Verifier 和 User Agent 的职责不同。
Verifier 判断的是 “客观状态是否正确”:数据库里有没有记录、文件是否生成、字段是否匹配、消息是否发出、权限是否符合预期。
User Agent 判断的是 “用户意图是否被满足”:Agent 有没有问对澄清问题、有没有在错误方向上走太远、有没有忽略用户补充、有没有在频道里制造困惑。两者结合,才更接近真实产品质量。
频道协作里最重要的往往不是某一句话的质量,而是系统在多轮、多主体、多工具、多状态下能不能稳定闭环。
最后
Agent Channel 的本质,是一种 agent-human 协作方式。
群聊只是表面形态,真正重要的是它把 Agent 放进了一个更接近真实工作的空间:人可以自然表达需求、补充信息和检查结果,Agent 可以被明确投递任务、读取结构化上下文、调用工具并回到同一个协作现场。多人协作、异步投递、长期上下文、工具执行、附件流转、权限控制和身份来源链路,都只是为了支撑这种协作方式。
所以从对话框到频道,不是把 UI 从单列消息改成多人消息,也不是让 Agent 学会在回复里多 @ 几个人。它要求系统重新回答几个基础问题:
- 谁在说话?
- 这条消息应该投递给谁?
- Agent 能看到哪些上下文?
- 它能调用哪些工具?
- 行为是否可恢复、可验证、可追踪?
- 用户意图是否真的被满足?
好的 Agent 产品最终不只是更会聊天,而是更能在多人、多工具、多状态的环境中持续推进任务,背后的产品约束、系统协议和验证机制很值得认真设计。