


背景
Generative UI = 用 AI 把 “一句话需求” 实时翻译成可交互的界面,并可随用随改。
比如:
- 说 “我要看北京天气” → 立刻出现天气卡片 — 这是根据自然语言即时渲染组件,动态界面生成
- “再加一个素食选项”→ 立即出现勾选框 — 需求变了,界面秒级长出新输入框
- 股票价刷新 → 走势图实时重绘 — 数据变,界面自动跟着变
- …
在 Agent 产品中相当有用,想象一个股票助理 Agent,从看 “特斯拉股价” → 实时股价卡片 + 折线图 + 买卖按钮,可直接在 Agent 界面中下单。
这背后就引出了 Generative UI 的话题,实现上有些差异,可以大致分为工具驱动型 Generative UI 和 模型驱动型 Generative UI。
工具驱动型 Generative UI
典型代表:Amazon Bedrock、Vercel AI SDK。
LLM 不直接写代码,而是像「调度员」一样,判断要干啥 → 然后选工具 → 把工具返回的数据塞进现成的 UI 组件里:
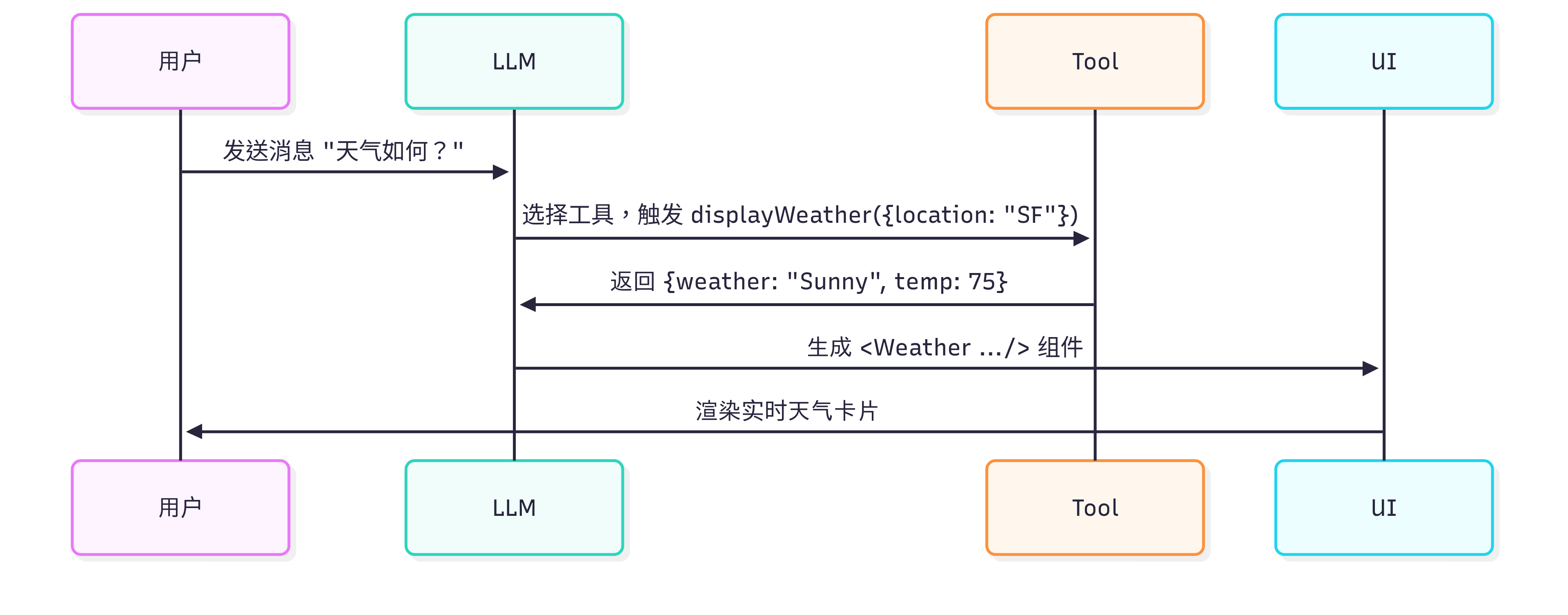
从实现上看,Agent 系统的工具区分出了后端工具和前端工具,前端工具是一套严格定义的组件库,和后端工具一起作为 Agent 的供应链,只要前端有一个天气渲染组件,Agent 后端具备获取天气的能力,那么 Agent 就能在返回天气数据时把天气渲染组件的名称 or id 一起给到前端,前端通过组件名称 or id 实例化天气组件,然后用一个标准化的 result 填充进去即可。
前端工具 = 带 Schema 的函数:
export const weatherTool = createTool({
description: 'Display the weather for a location',
parameters: z.object({ location: z.string() }),
execute: async ({ location }) => /* … */,
});
执行函数、React/Vue 组件渲染:
{message.toolInvocations?.map(inv => {
if (inv.toolName === 'displayWeather' && inv.state === 'result') {
return <Weather key={inv.toolCallId} {...inv.result} />;
}
})}
从运行时上看,只有 “组合” 与 “数据填充”,不会 “现场造轮子”,扩展前端工具集就能扩展 UI 的表现层,加一个 stockTool → 渲染 <Stock/>,再加一个 calendarTool → 渲染 <Calendar/>,所有组件都能随对话即时出现。
工具驱动型 Generative UI 很像传统的 MVVM 架构,可以把它看成 MVVM 的 AI 时代升级版,差异主要体现在 “谁来写 ViewModel” 和 “谁来触发命令” 这两点上:
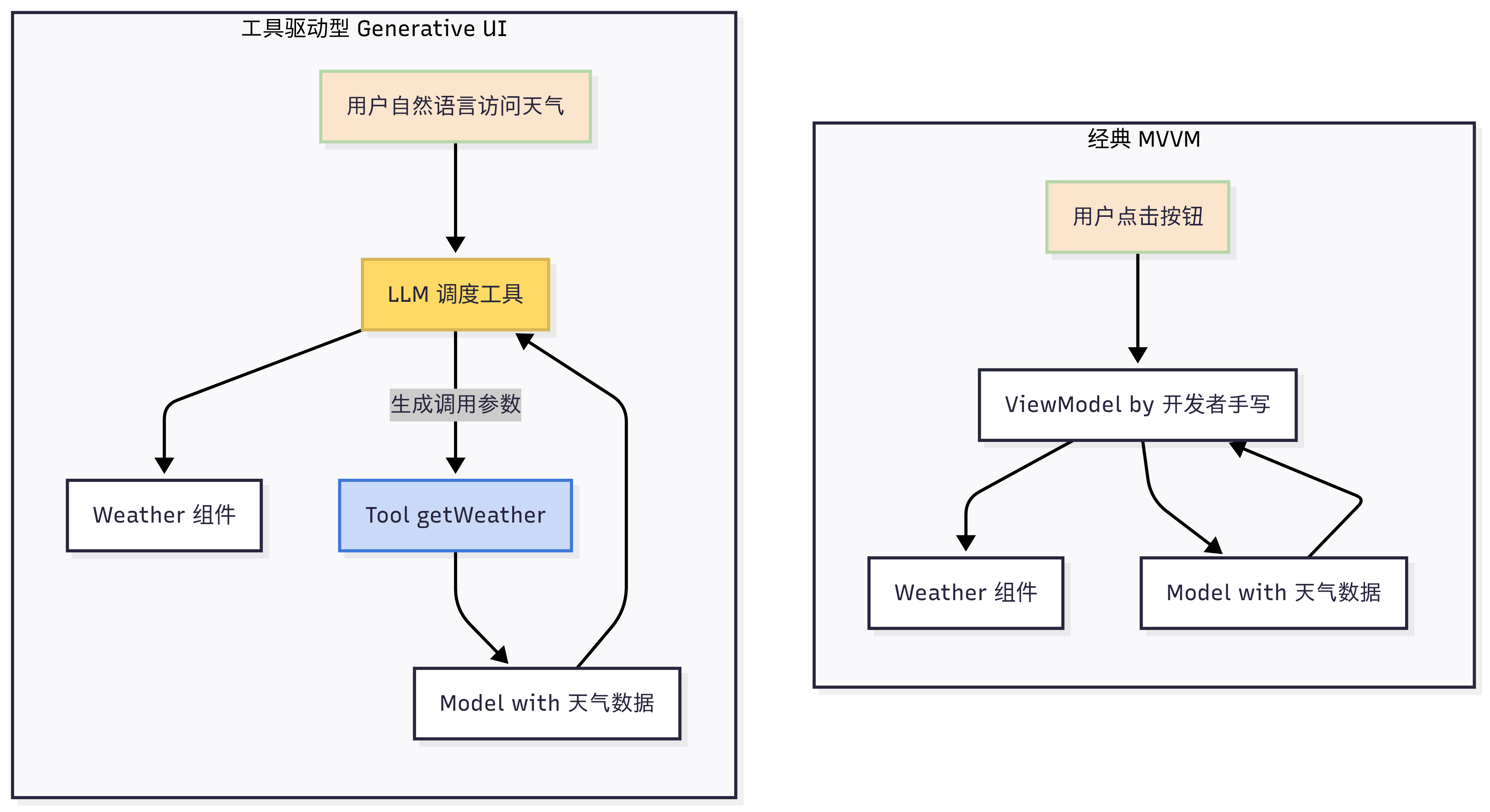
骨架没变(M-V-VM 三层仍在),VM 层被 LLM 动态拼装,从而让用户用自然语言就能 “零代码” 驱动界面。
模型驱动型 Generative UI
Generative and Malleable User Interfaces with Generative and Evolving Task-Driven Data Model
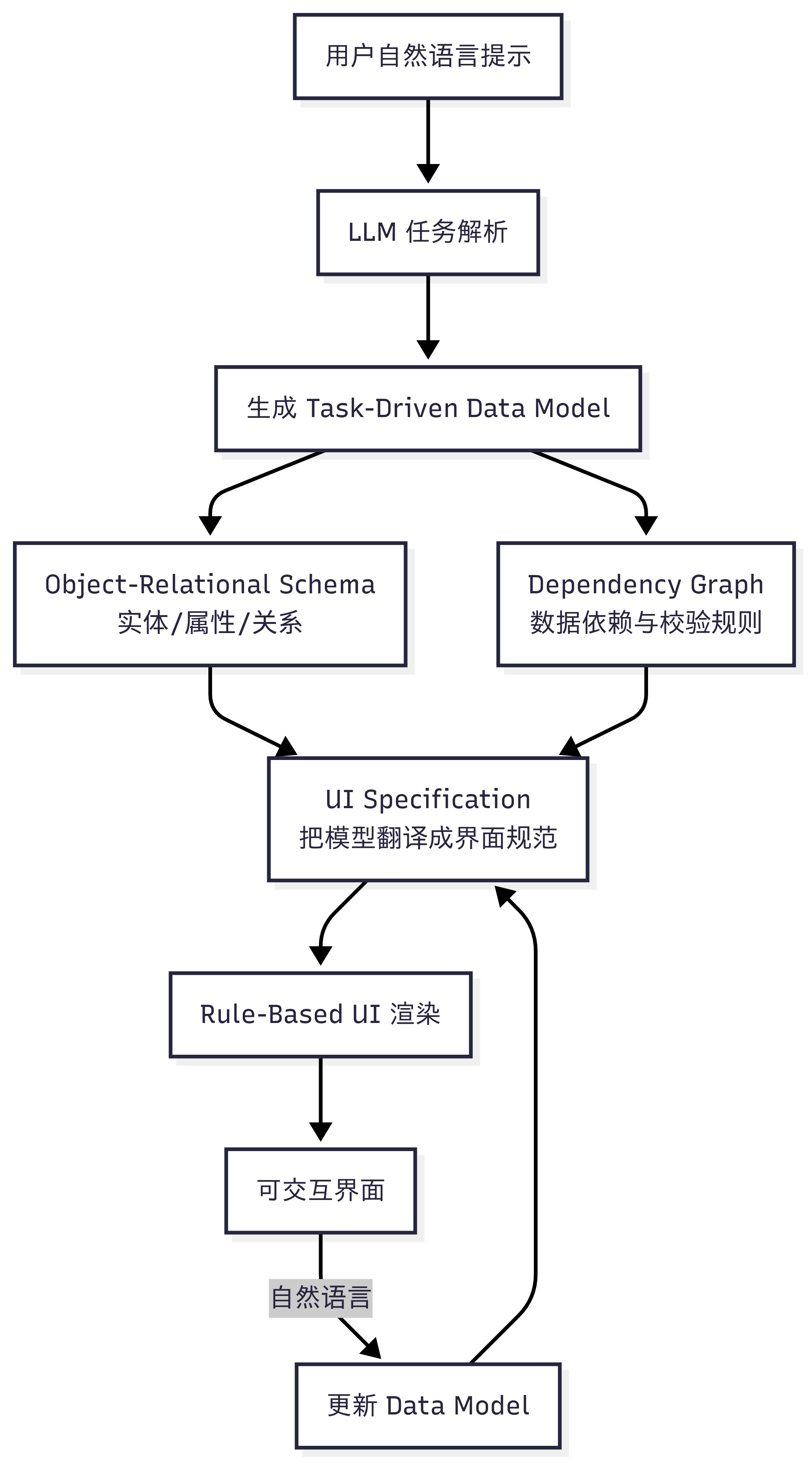
相比工具驱动型 Generative UI,模型驱动型 Generative UI 就属于 “现场造轮子” 了,它的理念是:与其使用固定的前端组件/代码,不如用 AI 先把 “任务” 抽象成可演化的数据模型,再由这个数据模型驱动 UI 界面的动态生成与随时修改:
- 模型先把需求转化成任务数据模型,明确有哪些实体、属性、关系、约束,例如 “我要办晚宴” → 会出现 Guest、Dish、ShoppingList 这些实体,以及 “忌口影响菜品” 这类依赖
- 模型再驱动 UI 生成,有了数据模型,系统按既定规则把实体映射成界面,Guest → 联系人卡片列表,Dish → 可勾选菜单,ShoppingList → 地图+清单
- 模型可随用户继续演化,用户随时用自然语言修改实体或数据(如 “再加两位素食朋友”),模型立即更新,界面跟着实时变化,无需重写代码
不得不说,思路和传统软件开发里的 Domain-Driven Design 是一样的,先基于需求理解建立领域模型(蓝图),再利用领域模型驱动 UI:
论文中的示例 — “给我一周膳食计划”,然后搞出了右边的 UI:
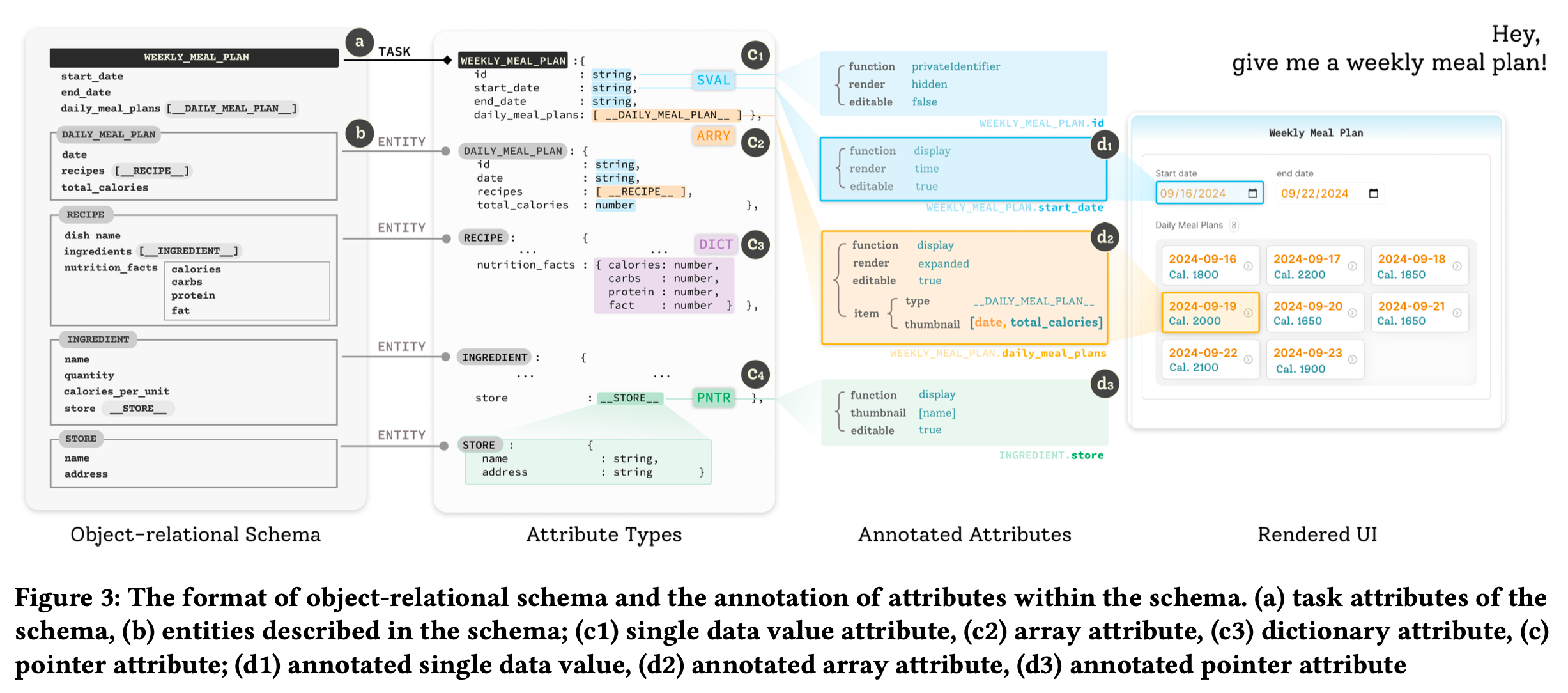
注:SVAL = 单值,ARRY = 数组,DICT = 键值,PNTR = 引用其他实体
先拆出实体模型:
| 实体 | 属性示例(部分) |
|---|---|
| WeeklyMealPlan | start_date, end_date, daily_meal_plans(ARRAY) |
| DailyMealPlan | date, recipes(ARRAY) |
| Recipe | name, calories, ingredients(ARRY), cuisine_type |
| Ingredient | name, store(PNTR) |
| Store | name, address |
建立 Dependency Graph:
- 校验型,如 Checkout 日期必须 ≥ Check-in
- 更新型,如 Ingredient 数量变 → Recipe 总热量自动重算
从领域模型到 UI,第一步,先标注,每个属性被打上 <function, render, editable> 标签:
- start_date → <display, time, true> → 渲染成可编辑日历
- guest_list → <display, expanded, true> → 直接展开联系人卡片
第二步,UI 控件映射:
| 标签组合 | 对应 UI 控件 |
|---|---|
<display, number, true> | 数字输入框 |
<display, location, true> | 地图选点 |
<display, summary, true> | 折叠按钮 + 弹窗详情 |
pipeline 如下:
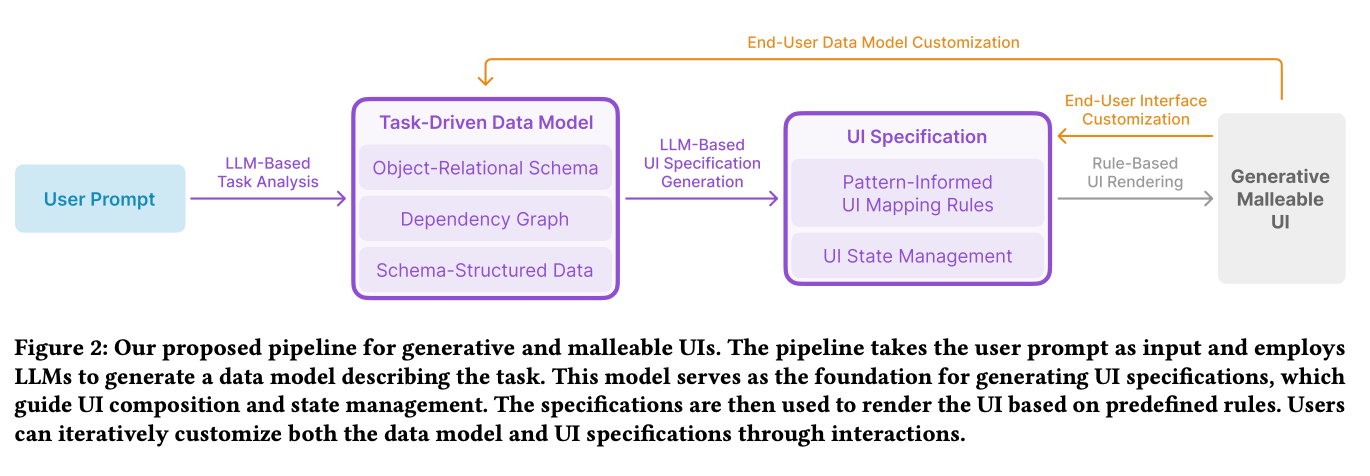
一个是做任务理解、领域建模的 LLM,一个是基于前者画 UI 的 LLM,再搭配一个前端的 UI 控件库。
两种方式对比
| 维度 | AI-SDK 做法(工具驱动) | 论文做法(模型驱动) |
|---|---|---|
| 新增字段/实体 | 必须事先把 tool 规范(函数 + React 组件)写好;运行时 LLM 只能 “调用” 工具,不能 “发明” 工具 | LLM 先把需求抽象成可演化的数据模型(Schema),再按规则自动映射出 UI;字段可随时增删。 |
| UI 组件来源 | 开发者预先写死 <Weather/>、<Stock/> 等,LLM 仅决定 “用哪一个” | 系统根据数据类型和规则自动生成或组合组件,无需提前枚举 |
| 扩展成本 | 每新增一个实体(如 “忌口”)和展现形式时,要加或者更新 Tool | 复用或更新可映射的 UI 控件库 |
| 适用场景 | 垂直类、确定型任务(天气、股票、航班查询) | 开放式任务(办晚宴、做研究、旅行规划) |
两种方式都没办法完全由 LLM 在运行时造轮子,但模型驱动的扩展性稍微更好一些:
- 工具驱动型 UI 控件,是业务组件粒度;模型驱动型 UI 控件,是更细粒度的「渲染规则」
- 前端有大量可直接复用的组件库,比如国内的 Ant Design,不用人为写组件和造控件级别的轮子
所以只要「任务理解到位、建模 ok、懂 UI 设计」,LLM 按「数据类型 + 展示意图」自动拼装出 React/Vue 组件即可。
但问题是,要做好「任务理解到位、建模 ok、懂 UI 设计」这三件事也并不容易,特别是 UI 设计不仅是能看、能用,还得满足公司设计团队的要求,所以也不简单。