


背景
近年来,基于自然语言指令的图像编辑(Instruction-based Image Editing)应运而生,它允许用户通过简单的文本描述来修改图片,极大地降低使用门槛。使用方便了,却在精准度、性能、效率上面临很多挑战,基于大规模微调的方法虽然能达到较高精度,但训练样本和计算资源庞大;Training-Free 的方法虽然成本较低,却常常难以准确理解复杂的编辑指令,导致最终效果不太行。如何让模型真正 “理解” 图像内容和用户的修改意图,实现上下文感知的、自然的编辑,是研究者们持续探索的方向。
ICEdit 作为一个崭露头角的解决方案,它通过引入 In-Context Editing Framework、LoRA-MoE 混合微调以及 VLM-Guided Noise Selection 等技术,实现了对用户指令的深刻理解、对图像修改区域的精准定位,并最终高效完成高质量的图像编辑任务。
基石:DiT 与 In-Context Editing Framework
ICEdit 的底层架构依赖于一个大规模预训练的 Diffusion Transformer (DiT) 模型,DiT 结合了扩散模型强大的图像生成能力和 Transformer 架构卓越的序列处理与注意力机制,使其能够统一处理图像和文本两种模态的输入数据,在具体选择上,ICEdit 使用的是 FLUX.1 Fill DiT (12B 参数),FLUX.1 Fill 能在少量步骤内生成高质量的图像,并且具有强大的上下文感知能力,能够理解并处理图像和文本之间的关系。
FLUX.1 Fill 示例代码:
import torch
from diffusers import FluxFillPipeline
from diffusers.utils import load_image
image = load_image("https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/cup.png")
mask = load_image("https://huggingface.co/datasets/diffusers/diffusers-images-docs/resolve/main/cup_mask.png")
pipe = FluxFillPipeline.from_pretrained("black-forest-labs/FLUX.1-Fill-dev", torch_dtype=torch.bfloat16).to("cuda")
image = pipe(
prompt="a white paper cup",
image=image,
mask_image=mask,
height=1632,
width=1232,
guidance_scale=30,
num_inference_steps=50,
max_sequence_length=512,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"flux-fill-dev.png")
ICEdit 在 FLUX.1 Fill 的基础上引入了 In-Context Editing Framework,这个框架的核心思想是将图像编辑表述为一个条件生成任务,其关键在于构建一种被称为 IC Prompt 的输入提示:“A diptych with two side-by-side images of the same scene. On the right, the scene is exactly the same as on the left but {instruction}”。
IC Prompt 描述的左半部分是原始参考图像,右半部分则初始为空白、噪声或者待编辑区域,然后将用户的编辑指令(例如 “让她戴上墨镜”)经过文本编码器(如 T5)处理后,与这个图像输入一同送入 DiT,DiT 的任务是根据编辑指令生成同一图像调整后的版本:
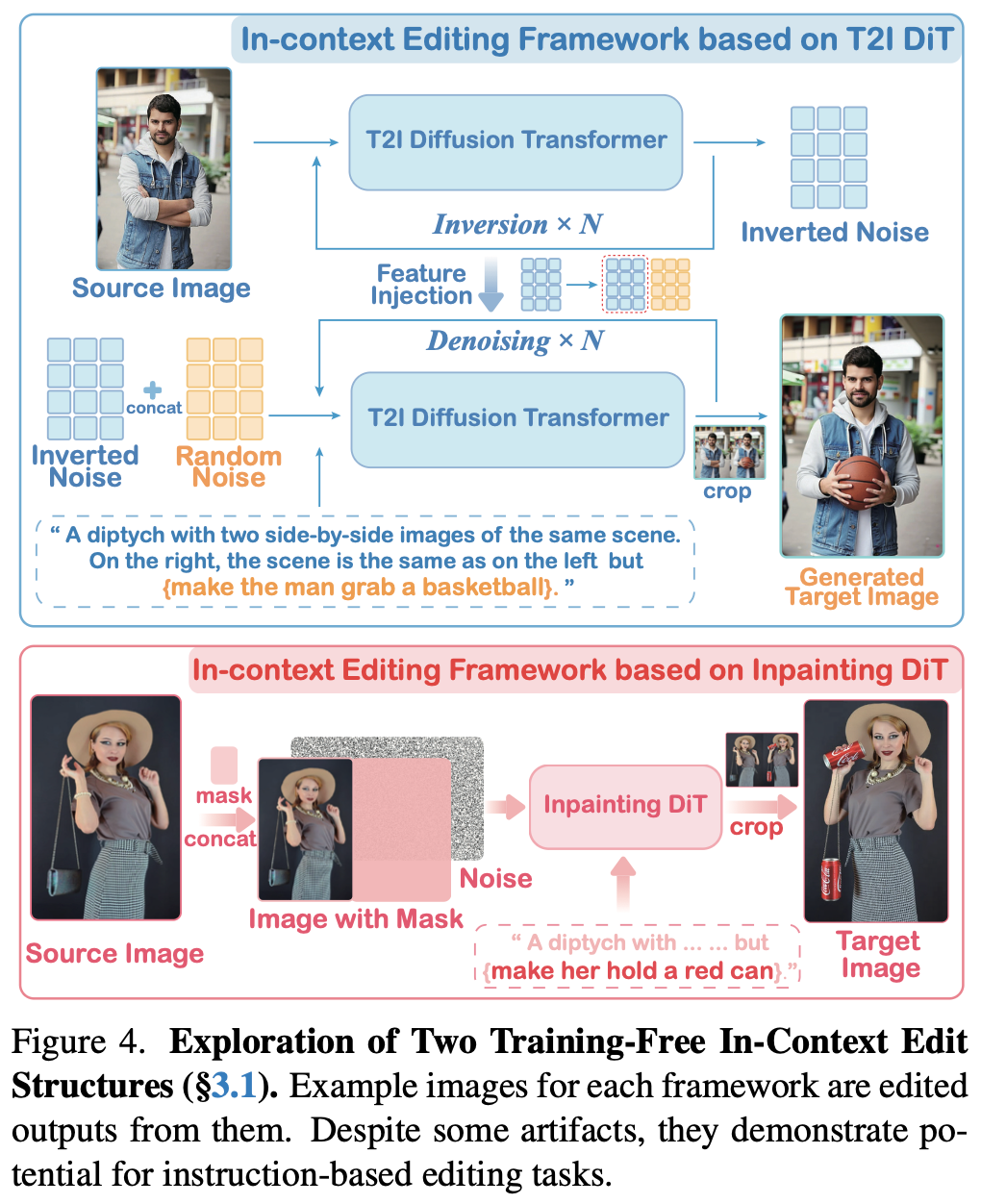
ICEdit 的使用示例:
python scripts/inference.py --image assets/girl.png \
--instruction "Make her hair dark green and her clothes checked." \
--flux-path /path/to/flux.1-fill-dev \
--lora-path /path/to/ICEdit-normal-LoRA
这个框架的另一大优势在于零样本指令遵从 (Zero-shot Instruction Compliance),它能在不引入新的网络模块或进行大量针对性微调的情况下,就能实现对编辑指令的理解和执行,这主要得益于 DiT 模型本身强大的上下文理解能力 (Contextual Awareness) 和内置的注意力机制,模型通过关注指令文本和源图像的相关区域,自然地推断出编辑意图。
是一个很巧妙的设计~
LoRA-MoE Hybrid Tuning - 兼顾效率与效果的精调策略
你或许注意到了上述使用示例中的 --lora-path 参数,尽管 In-Context Editing Framework 为零样本编辑提供了可能,但为了进一步提升模型在处理复杂、精细编辑任务时的表现,同时保持高效,ICEdit 引入了一种名为 LoRA-MoE Hybrid Tuning 的策略:
- 通过一个小型、可学习的门控网络(Gating Network),根据当前的视觉标记(Visual Tokens)和文本嵌入(Text Embedding),动态地决定激活哪个或哪些专家来处理当前的编辑任务
- 每个专家专注于特定类型的编辑行为,例如一个专家可能擅长颜色或风格的改变,另一个专家则可能精于物体的添加或移除
门控网络根据具体的编辑任务,动态地将任务路由给最合适的专家进行处理,保持计算效率,同时也使各个专家能专注于不同的任务特征,提高编辑的多样性和准确性。
VLM-Guided Noise Selection - 提升编辑质量的关键一步
ICEdit 在推理阶段引入了一项巧妙的优化技巧 —— 基于 VLM 引导的噪声选择(VLM-Guided Noise Selection),也被称为 Early Filter Inference-Time Scaling,不过这项能力似乎还没有开源?
从论文中看,其实就是 Inference-Time Scaling for Diffusion Models,在扩散模型的生成过程中,初始噪声的选择对最终图像的生成 & 编辑结果有着显著影响,有些噪声能够引导模型产生更准确、更符合指令的编辑,而另一些则可能导致不满意的结果。但重要的是,一个编辑任务 “是否有效” 往往在扩散过程的早期几个步骤(例如4-10步)就能初见端倪,这就给了 ICEdit 优化空间:
- 首先,系统会生成多个候选的初始噪声
- 然后,对每个候选种子都执行少量的扩散步骤,得到一系列部分生成的、初步的编辑结果
- 接下来,利用一个强大的 VLM (例如 Qwen2.5-VL-72B,原文提及 Qwen-VL-72B,推测为 Qwen2.5-VL-72B),来评估这些初步的、部分生成的图像结果与用户原始编辑指令的匹配程度。VLM 会对比哪两个噪声生成的结果更符合指令,胜者再与其余噪声产生的结果进行比较,以此类推,最终选出最佳的噪声
- 一旦 VLM 选定了与指令最匹配的那个初始噪声,系统便会使用这个 winner 来完成整个去噪过程,生成最终的编辑图像
这种策略,通过在扩散过程的早期阶段就剔除掉那些可能导致不良编辑结果的噪声,有效避免了在错误的生成路径上浪费计算资源。更重要的是,它能显著提高最终编辑结果与用户指令的一致性和准确性,从而提升了整体的编辑质量和鲁棒性。
最后
ICEdit 核心技术关键要点:
- Diffusion Transformer (DiT) 与 In-Context Editing:利用 DiT 统一处理图像和文本,通过 IC Prompt 实现零样本指令遵从和上下文感知
- LoRA-MoE Hybrid Tuning:结合 LoRA 和 MoE 的动态专家路由,以极少额外参数实现对多样化编辑任务的灵活适应和精细调控
- VLM-Guided Noise Selection:在推理时,通过 VLM 评估并选择最佳初始噪声,从早期阶段优化生成路径,提升最终编辑质量和指令遵循度
ICEdit 以前所未有的低门槛,让复杂的图像修改任务变得像与 Chatbot 对话一样简单自然,无论是专业设计师还是普通用户,都能够轻松释放创意,实现个性化的视觉表达。作为一个强大的开源工具,ICEdit 也展示出了当前 AI 图像编辑技术所能达到的高度,期待不断演进和完善。