


从杭州返程回厦门,天空真好看
OpenManus
整体概览
从用户给定一个任务,到它跑起来的大致过程:
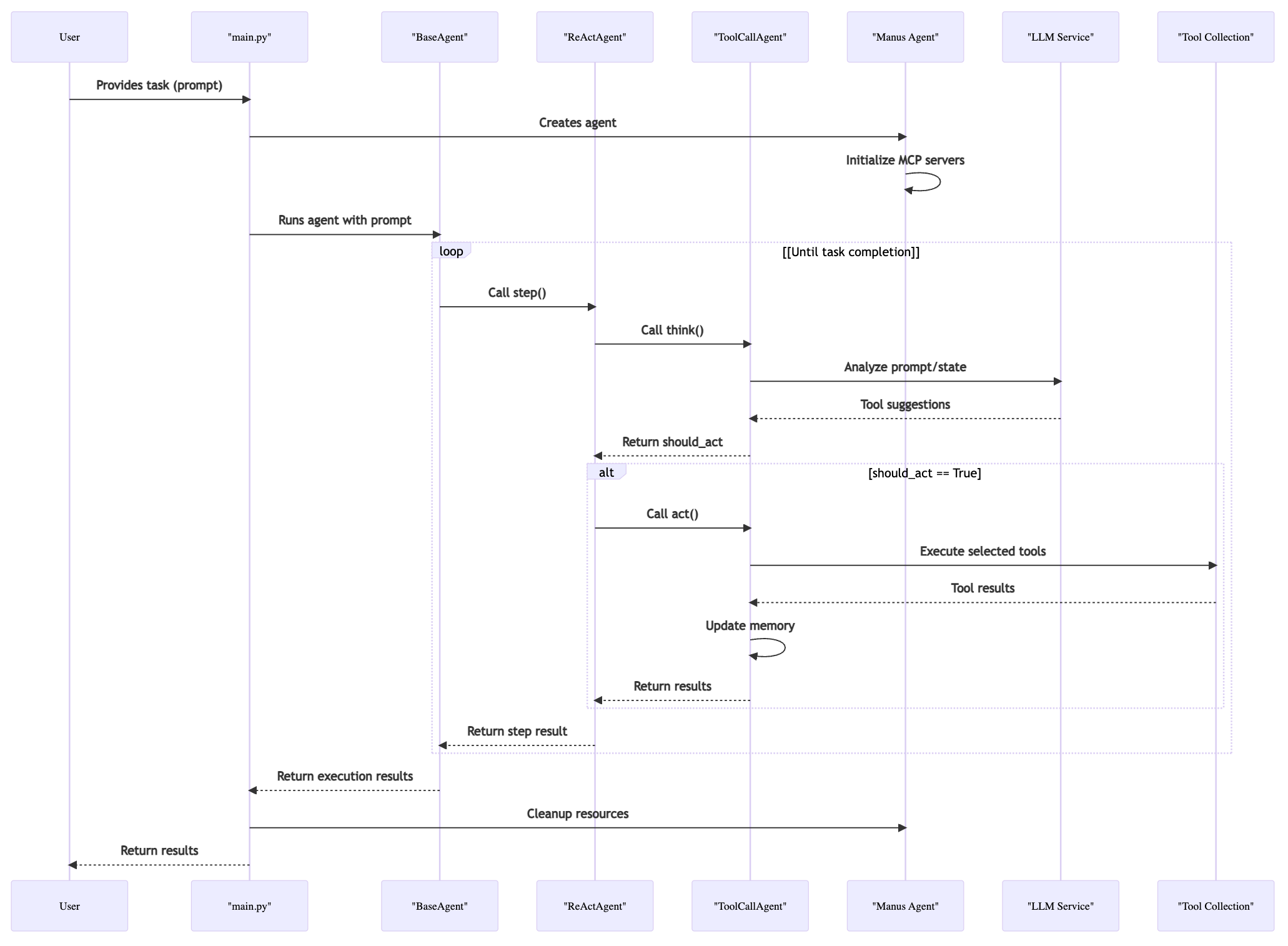
核心组件之间的关系
OpenManus 在实现 Agent 的时候,设计了一套严谨的继承关系:
- BaseAgent,是所有 Agent 的抽象基类,定义了核心属性和生命周期管理方法,以及统一的接口和基础能力,如 run 函数
- ReActAgent,实现了 “反思-行动(ReAct)” 范式,支持 Agent 在每一步决策时既能思考(反思)也能调用工具(行动)
- 它强制让子类实现了思考(think)和行动(act)的分离
- 也支持 “只思考不行动” 的场景
- ToolCallAgent,在 ReActAgent 基础上,增强了对工具调用的抽象,支持多工具选择、调用和结果处理
- Manus,是通用型智能体,支持本地和远程(MCP)工具的统一调用,具备强大的通用任务解决能力
此外,面向工具的核心组件主要有两个:
- ToolCollection,统一管理工具集(BaseTool),支持批量添加、查找、执行等操作
- MCPClients,管理与多个 MCP(Model Context Protocol)服务器的连接
它们之间的关系如下:
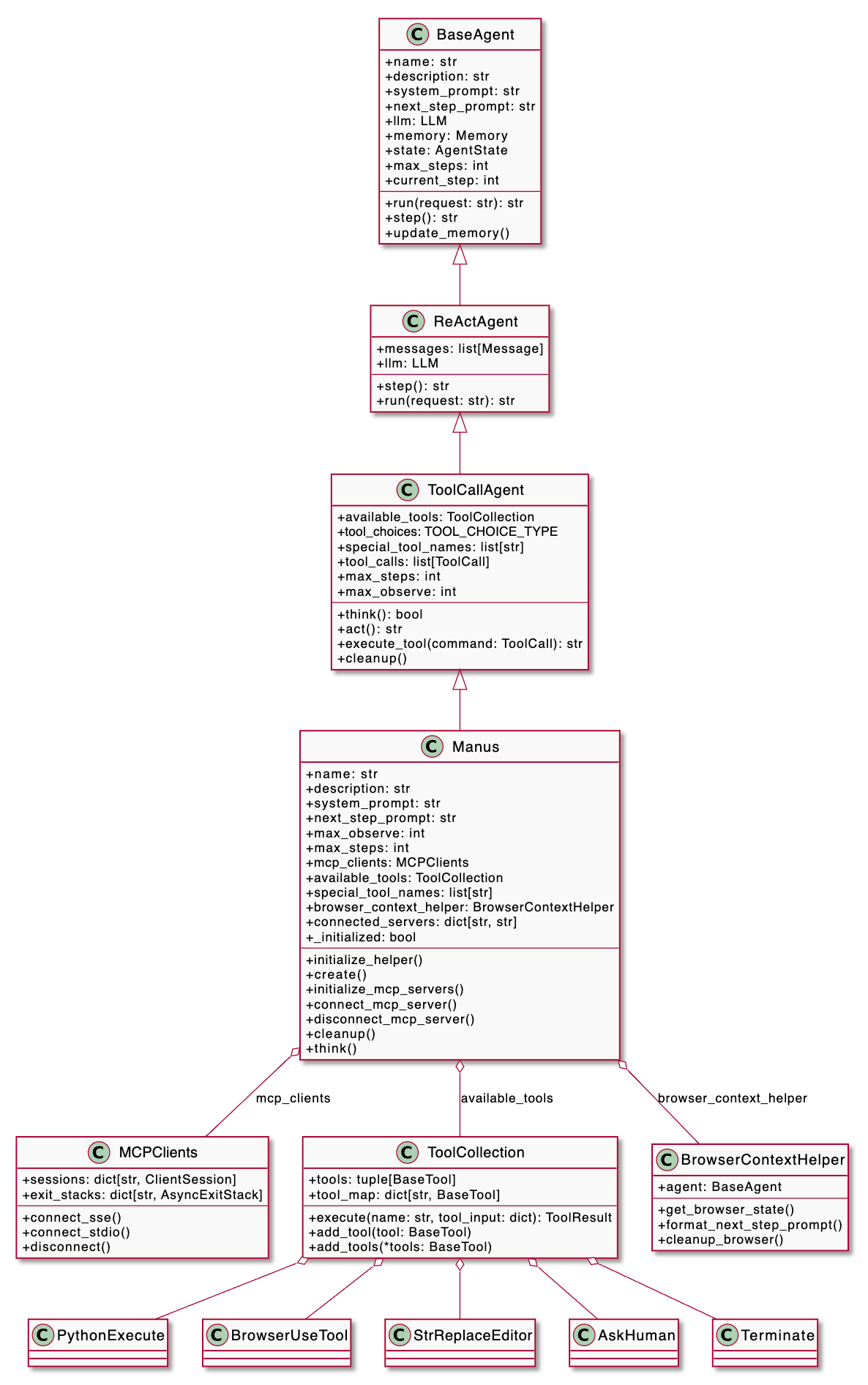
Agent 执行流程
可以看出来,执行不是在单个类或文件里以线性的方式串联,而是父子之间的协同:
- BaseAgent,run
- ReActAgent,step
- ToolCallAgent,think + act
- Manus,think
Manus 为了能够在执行不同类型任务时提供最合适的上下文信息给 LLM,覆写了 ToolCallAgent 的 think 方法:
async def think(self) -> bool:
"""Process current state and decide next actions with appropriate context."""
if not self._initialized:
await self.initialize_mcp_servers()
self._initialized = True
original_prompt = self.next_step_prompt
recent_messages = self.memory.messages[-3:] if self.memory.messages else []
browser_in_use = any(
tc.function.name == BrowserUseTool().name
for msg in recent_messages
if msg.tool_calls
for tc in msg.tool_calls
)
if browser_in_use:
self.next_step_prompt = (
await self.browser_context_helper.format_next_step_prompt()
)
result = await super().think()
# Restore original prompt
self.next_step_prompt = original_prompt
return result
它检测最近 3 条消息中是否使用了 BrowserUseTool,如果使用了,则将动态替换提示词为包含浏览器状态的版本,如:
- 当前页面 URL 和标题
- 可用标签页数量
- 页面滚动状态(上方/下方还有多少像素内容)
- 当前浏览器截图(如果有)
是一个比较智能的提示词优化方法,只在需要时获取浏览器状态,避免不必要的开销,但能帮助 LLM 提高决策质量和执行效果。
我们从主循环开始,看看它们之间的整体串联细节:

Memory 的设计
OpenManus 将 memory 按 role 分为四种:user、system、assistant、tool,每种 role 的消息最多只保存 100 条,FIFO,且支持存储图像(用于浏览器截图)。
由于 Agent 在设计上的多态性(面向对象),Memory 也是由不同的类来更新的:
- BaseAgent 层,初始化时,在 run 里添加 user 消息,还负责实现卡死检测
- ToolCallAgent 层,next_step_prompt 作为 user 消息,LLM 的响应、Tool 的执行作为 assistant、tool 消息
- Manus 层,实现上下文感知,动态修改 next_step_prompt,以及处理浏览器截图的图像数据
Memory 还可以帮助 Agent 实现卡死检测:
def is_stuck(self) -> bool:
"""检测智能体是否陷入循环"""
if len(self.memory.messages) < 2:
return False
last_message = self.memory.messages[-1]
if not last_message.content:
return False
# 统计相同内容的出现次数
duplicate_count = sum(
1
for msg in reversed(self.memory.messages[:-1])
if msg.role == "assistant" and msg.content == last_message.content
)
return duplicate_count >= self.duplicate_threshold
针对卡死的处理策略:
def handle_stuck_state(self):
"""处理卡死"""
stuck_prompt = "Observed duplicate responses. Consider new strategies..."
self.next_step_prompt = f"{stuck_prompt}\n{self.next_step_prompt}"
Prompts
OpenManus 把 prompt 分为了 System Prompt 和 Next Step Prompt:
- System Prompt,角色定义,设定 Agent 的基本人格和行为模式,告诉 LLM “你是谁”,以此定义了 Agent 的身份、能力和总体行为准则
- Next Step Prompt,行动指导,告诉 LLM “现在应该做什么”,指导当前步骤的具体行为,在每次 think 方法中作为 user 消息发送
详细区别如下表:
| 特性 | SYSTEM_PROMPT | NEXT_STEP_PROMPT |
|---|---|---|
| 消息类型 | System Message | User Message |
| 变化频率 | 静态,会话期间不变 | 动态,每步可能变化 |
| 作用范围 | 全局角色定义 | 当前步骤指导 |
| 内容重点 | “你是谁” + “你能做什么” | “现在做什么” + “怎么做” |
| 上下文感知 | 通常固定 | 可根据状态动态调整 |
这样设计的好处是:
- 职责分离了,系统提示词负责身份定义,步骤提示词负责行动指导tool
- 灵活性高,步骤提示词可以根据上下文动态调整(如 Manus 的浏览器感知)
- 可维护性高,两种提示词可以独立修改和优化
Manus 的 prompts 定义如下:
| 分类 | 内容 |
|---|---|
| System Prompt | You are OpenManus, an all-capable AI assistant, aimed at solving any task presented by the user. You have various tools at your disposal that you can call upon to efficiently complete complex requests. Whether it’s programming, information retrieval, file processing, web browsing, or human interaction (only for extreme cases), you can handle it all.The initial directory is: {directory} |
| Next Step Prompt | Based on user needs, proactively select the most appropriate tool or combination of tools. For complex tasks, you can break down the problem and use different tools step by step to solve it. After using each tool, clearly explain the execution results and suggest the next steps.If you want to stop the interaction at any point, use the terminate tool/function call. |
Qwen-Agent
整体流程
设计上和 OpenManus 大同小异,直接看完整链路是如何串联的:
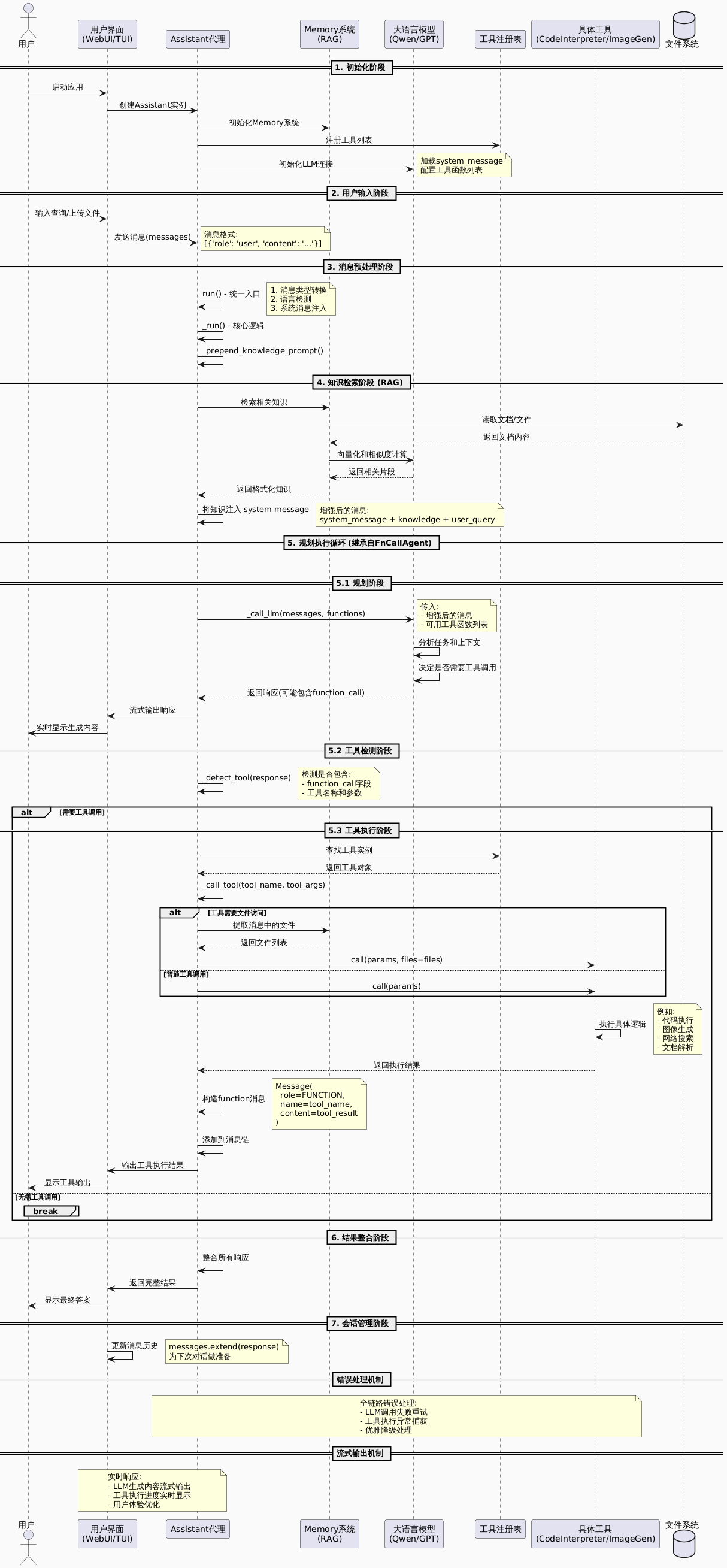
除了 Assistant,还有一个简化版的 ReActChat,也实现了 ReAct 范式:
def _run(self, messages, lang='en', **kwargs):
# 1. 构建 ReAct 提示模板
text_messages = self._prepend_react_prompt(messages, lang)
response = 'Thought: '
while num_llm_calls_available > 0:
# 2. LLM 生成思考过程
output = self._call_llm(messages=text_messages)
response += output[-1].content
# 3. 解析 Action 和 Action Input
has_action, action, action_input, thought = self._detect_tool(output)
if not has_action:
break
# 4. 执行工具获取 Observation
observation = self._call_tool(action, action_input)
response += f'\nObservation: {observation}\nThought: '
# 5. 更新消息继续推理
text_messages[-1].content += thought + f'\nAction: {action}...' + observation
但相比 Assistant,Assistant 不仅具备 规划 → 执行,而且在某些方面比 ReActChat 更强大:
- 结合了 RAG
- 自动化程度高,用户体验更好
- 与 Memory、多模态、MCP 等系统集成度更好
看起来就像这样:
用户输入 → [RAG 检索] → LLM 规划 → 工具执行 → 结果整合 → 输出
↑_____________反馈循环_____________↑
RAG
Qwen-Agent 有强大的 RAG 处理能力,支持以下文件:
- PDF (.pdf)
- Word文档 (.docx)
- PowerPoint (.pptx)
- 文本文件 (.txt)
- 表格文件 (.csv, .tsv, .xlsx, .xls)
- HTML文件
在处理流程上,先进行文档预处理:
def call(self, params):
# 1. 文件下载/读取
content = self._read_file(file_path)
# 2. 内容提取
text_content = self._extract_text(content, file_type)
# 3. 智能分块
chunks = self._split_content(text_content, page_size=500)
# 4. 构建元数据列表
records = []
for i, chunk in enumerate(chunks):
records.append({
'content': chunk,
'metadata': {
'source': file_path,
'chunk_id': i,
'page': page_num
}
})
return records
再从用户原始 query 中提取关键词,这一步主要是通过 prompt 让 LLM 提取:
请提取问题中的关键词,需要中英文均有,可以适量补充不在问题中但相关的关键词。
关键词尽量切分为动词、名词、或形容词等单独的词,不要长词组。
关键词以JSON的格式给出,比如:
{"keywords_zh": ["关键词1", "关键词2"], "keywords_en": ["keyword 1", "keyword 2"]}
Question: {user_request}
Keywords:
小 tips:
- 使用专门的 prompt 模板让 LLM 提取关键词
- 同时生成中文和英文关键词
- 补充相关但不在原问题中的关键词
- 将长词组分解为单独的词汇
然后采用混合检索策略,简化后的代码如下:
def sort_by_scores(self, query, docs):
chunk_and_score_list = []
# 1. 执行多种搜索策略
for search_obj in self.search_objs:
scores = search_obj.sort_by_scores(query, docs)
chunk_and_score_list.append(scores)
# 2. 分数融合算法
for i, (doc_id, chunk_id, score) in enumerate(chunk_and_score):
if score == POSITIVE_INFINITY:
final_score = POSITIVE_INFINITY
else:
# 倒数排名加权:1/(rank+60)
final_score += 1 / (i + 1 + 60)
# 3. 重新排序
return sorted(all_scores, key=lambda x: x[2], reverse=True)
再将召回的 chunks 以结构化的方式输出:
def format_knowledge_to_source_and_content(result):
knowledge = []
# 解析检索结果
for doc in result:
url, snippets = doc['url'], doc['text']
knowledge.append({
'source': f'[文件]({get_basename_from_url(url)})',
'content': '\n\n...\n\n'.join(snippets)
})
return knowledge
生成中英文模板:
# 中文模板
KNOWLEDGE_SNIPPET_ZH = """## 来自 {source} 的内容:
{content}
# 英文模板
KNOWLEDGE_SNIPPET_EN = """## The content from {source}:
{content}
注入到 system prompt 中:
def _prepend_knowledge_prompt(self, messages, lang='en', knowledge=''):
# 1. 获取检索知识
if not knowledge:
*_, last = self.mem.run(messages=messages, lang=lang)
knowledge = last[-1].content
# 2. 格式化知识片段
knowledge = format_knowledge_to_source_and_content(knowledge)
snippets = []
for k in knowledge:
snippets.append(KNOWLEDGE_SNIPPET[lang].format(
source=k['source'],
content=k['content']
))
# 3. 构建知识提示
knowledge_prompt = KNOWLEDGE_TEMPLATE[lang].format(
knowledge='\n\n'.join(snippets)
)
# 4. 注入系统消息
if messages and messages[0].role == SYSTEM:
messages[0].content += '\n\n' + knowledge_prompt
else:
messages = [Message(role=SYSTEM, content=knowledge_prompt)] + messages
return messages
支持超大上下文处理
如果 input 太大,支持智能截断,简化版逻辑如下:
def _truncate_input_messages_roughly(messages: List[Message], max_tokens: int):
# 1. 保护系统消息
if messages and messages[0].role == SYSTEM:
sys_msg = messages[0]
available_token = max_tokens - _count_tokens(sys_msg)
else:
available_token = max_tokens
# 2. 从最新消息开始保留
new_messages = []
for i in range(len(messages) - 1, -1, -1):
if messages[i].role == SYSTEM:
continue
cur_token_cnt = _count_tokens(messages[i])
if cur_token_cnt <= available_token:
new_messages = [messages[i]] + new_messages
available_token -= cur_token_cnt
else:
# 3. 对超长消息进行智能截断
if messages[i].role == USER:
_msg = _truncate_message(messages[i], max_tokens=available_token)
if _msg:
new_messages = [_msg] + new_messages
break
elif messages[i].role == FUNCTION:
# 工具结果保留首尾重要信息
_msg = _truncate_message(messages[i], max_tokens=available_token, keep_both_sides=True)
if _msg:
new_messages = [_msg] + new_messages
return new_messages
def _truncate_message(msg: Message, max_tokens: int, keep_both_sides: bool = False):
if isinstance(msg.content, str):
content = tokenizer.truncate(msg.content, max_token=max_tokens, keep_both_sides=keep_both_sides)
else:
text = []
for item in msg.content:
if not item.text:
return None
text.append(item.text)
text = '\n'.join(text)
content = tokenizer.truncate(text, max_token=max_tokens, keep_both_sides=keep_both_sides)
return Message(role=msg.role, content=content)
RAG 也支持超大上下文:
class ParallelDocQA(Assistant):
"""并行文档问答,支持超长文档"""
def _parse_and_chunk_files(self, messages):
valid_files = self._get_files(messages)
records = []
for file in valid_files:
# 大块分割,适合并行处理
_record = self.doc_parse.call(
params={'url': file},
parser_page_size=PARALLEL_CHUNK_SIZE, # 1000 tokens per chunk
max_ref_token=PARALLEL_CHUNK_SIZE
)
records.append(_record)
return records
def _retrieve_according_to_member_responses(self, messages, user_question, member_res):
# 基于 member 响应进行二次检索
keygen = GenKeyword(llm=self.llm)
member_res_token_num = count_tokens(member_res)
# 限制关键词生成输入长度
unuse_member_res = member_res_token_num > MAX_RAG_TOKEN_SIZE # 4500 tokens
query = user_question if unuse_member_res else f'{user_question}\n\n{member_res}'
# 生成检索关键词
*_, last = keygen.run([Message(USER, query)])
keyword = last[-1].content
# 执行检索
content = self.function_map['retrieval'].call({
'query': keyword,
'files': valid_files
})
return content
针对超长对话的处理:
class DialogueRetrievalAgent(Assistant):
"""This is an agent for super long dialogue."""
def _run(self, messages, lang='en', session_id='', **kwargs):
# 处理超长对话历史
new_messages = []
content = []
# 将历史对话转换为文档
for msg in messages[:-1]:
if msg.role != SYSTEM:
content.append(f'{msg.role}: {extract_text_from_message(msg, add_upload_info=True)}')
# 处理最新用户消息
text = extract_text_from_message(messages[-1], add_upload_info=False)
if len(text) <= MAX_TRUNCATED_QUERY_LENGTH:
query = text
else:
# 提取查询意图
if len(text) <= MAX_TRUNCATED_QUERY_LENGTH * 2:
latent_query = text
else:
latent_query = f'{text[:MAX_TRUNCATED_QUERY_LENGTH]} ... {text[-MAX_TRUNCATED_QUERY_LENGTH:]}'
# 使用LLM提取核心查询
*_, last = self._call_llm(
messages=[Message(role=USER, content=EXTRACT_QUERY_TEMPLATE[lang].format(ref_doc=latent_query))]
)
query = last[-1].content
# 保存对话历史为文件
content = '\n'.join(content)
file_path = os.path.join(DEFAULT_WORKSPACE, f'dialogue_history_{session_id}_{datetime.datetime.now():%Y%m%d_%H%M%S}.txt')
save_text_to_file(file_path, content)
# 基于文件进行RAG检索
return super()._run(messages=[messages[0]] + [Message(role=USER, content=query)], files=[file_path], **kwargs)
最后
OpenManus 采用模块化架构,包含三个主要层:Agent 层、Tool 层和 Prompt 层,层级分明,复杂度一般,注重模块化和可扩展性;相比之下,Qwen-Agent 更像一个完整的智能体生态系统,它支持 RAG 以及更复杂的多层检索,能通过逐步推理支持从 8K 到 100 万 token 的超大上下文处理(Generalizing an LLM from 8k to 1M Context using Qwen-Agent)。
两个框架的 Tool 设计差不多,也不太复杂,就不记录了。