


托草哥的福,拿到了一张免费的深圳 SECon 门票,于是 6 月底去学习了一番,个人认知有所提升~
今年 SECon 的主题是 “拥抱 AI、走深向实”,AI Agent、大模型、AIGC 基础设施相关的专场很多,本文主要记录 AI Agent 和大模型这两块儿的内容。
关于 AI Agent
Software 2.0 文章里提到,引入 AI 技术非常重要,因为未来主要是用数据集和神经网络训练的形式 “写” 代码,这句话里有两层含义:
- 软件是由代码组成的
- 代码是靠数据集和神经网络训练出来的
这两层含义的背后是一个本质:宇宙是一个规则简单的复杂系统。
在宏观尺度上,宇宙是由恒星、行星、星系等组成,这些天体又是由更小的粒子(如原子和亚原子粒子)构成,每一层次都有其独特的规律,层与层叠加之后的整体系统表现出比各部分之和更为复杂的行为。生命和神经网络也是如此,DNA 决定了生物的特征和功能,大量相互连接的神经元连接在一起实现了复杂的信息处理和学习能力。
问题在于,人的细胞、自我复制的能力是一个相当缓慢的过程,而算力和神经元的增长却非常快,本质上是碳基 vs 硅基。
人类对 Software 3.0 想象出的载体,就是 Agents - 智能体:

什么是 AI Agent
对 Agent 的定义,在大会上看到了无数张图及变种:
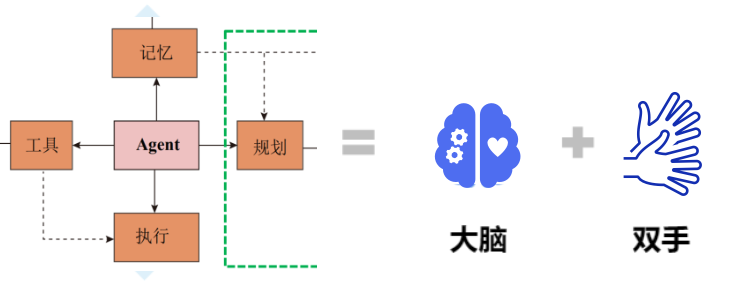
但同根同源,皆出自 2023 年的论文 LLM Powered Autonomous Agents:
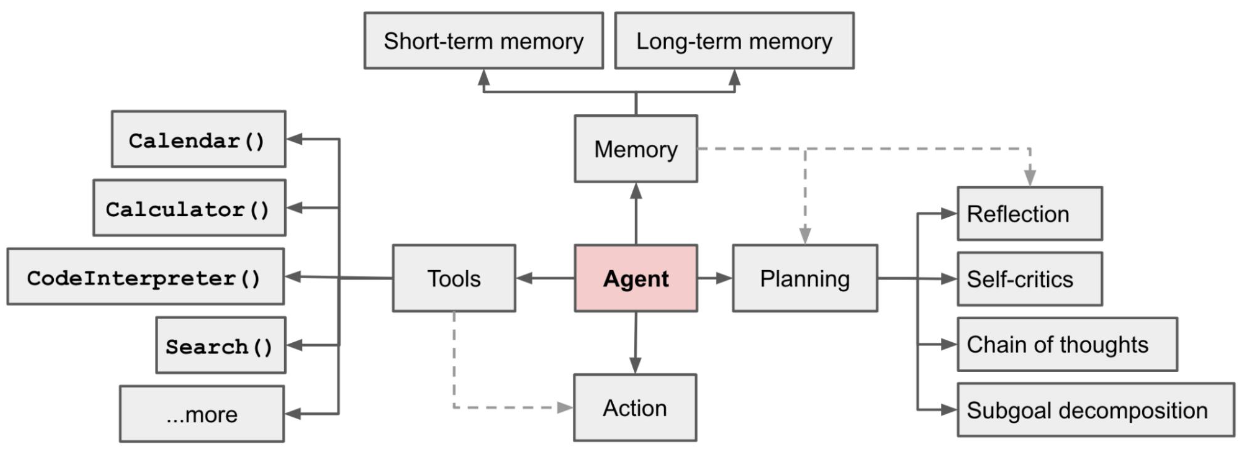
这套系统由四部分组成。
认知框架 Planning
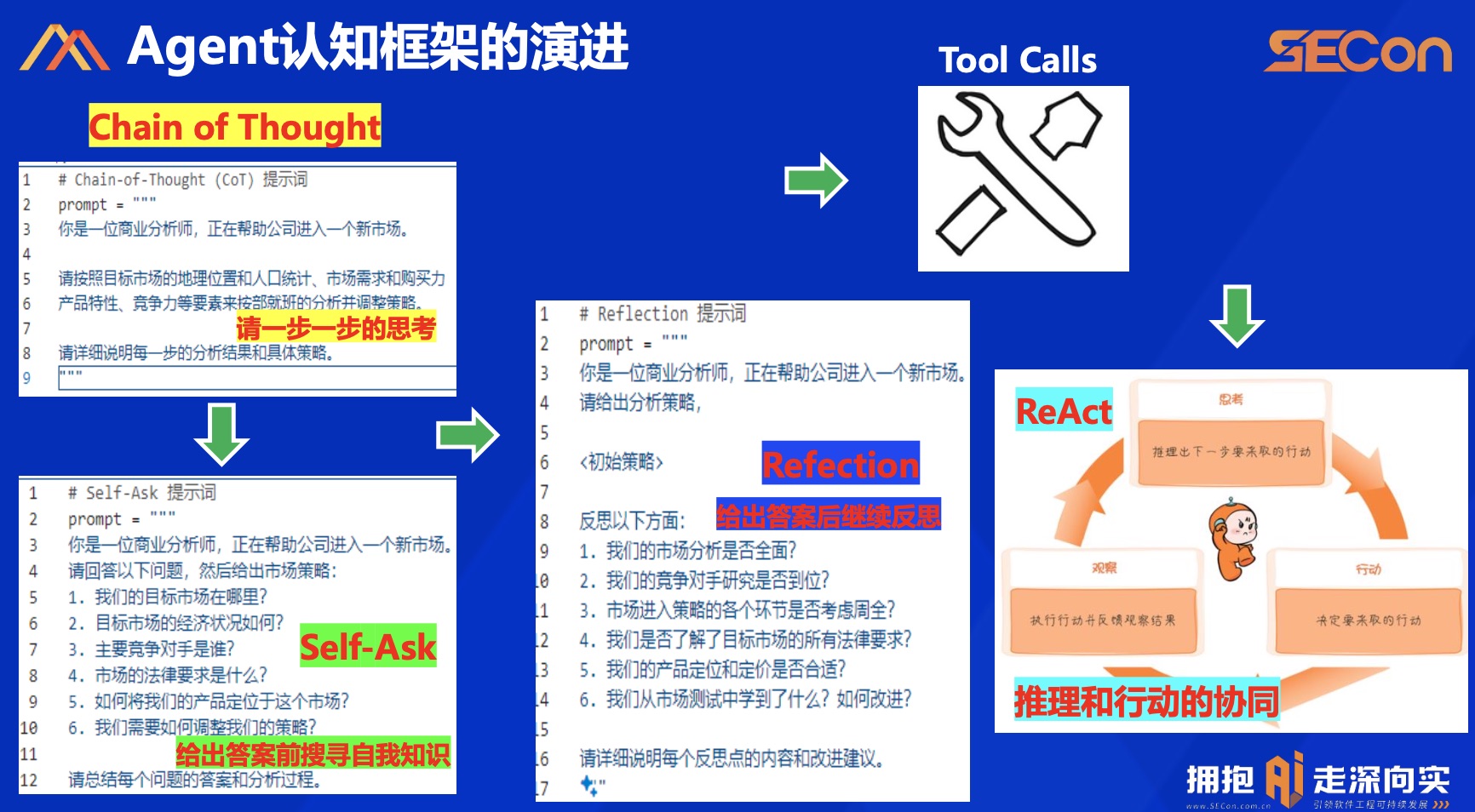
除了上图描述的,还有 ToT(Tree of Thoughts):
- 与 CoT 相比,ToT 通过对文本的探索和自我评估,进行多路径推理和决策,使 LM 能够进行有意识的决策
- ToT 在必要时进行前瞻或回溯,做出全局性的选择
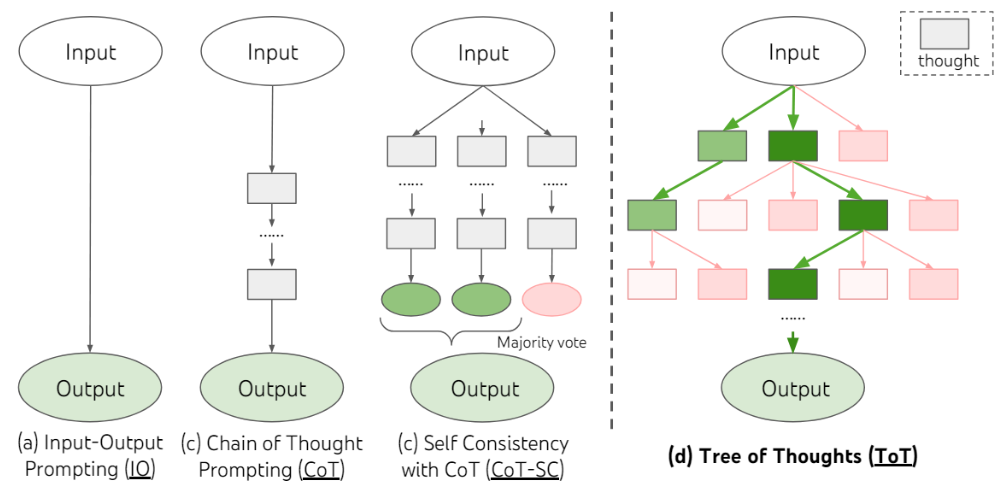
GoT(Graph of Thoughts):
- GoT 的核心思想在于将 LLM 生成的信息建模为任意图
- 信息单元(LLM thoughts)作为顶点,边表示这些顶点之间的依赖关系
- 将任意 LLM thoughts 结合成协同结果,提炼出整个思维网络的精髓,通过反馈循环增强思维
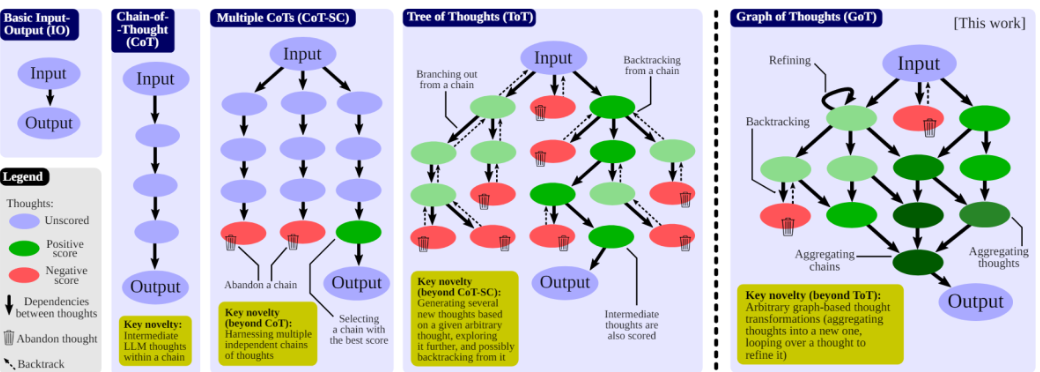
BoT(Buffer of Thoughts):
- 用 meta-buffer 存储一系列从各类任务的解决过程中提炼出的高层次信息思维模板,thought-template
- 检索相关的思维模板并自适应地实例化具体的推理结构以进行高效推理
记忆模块 Memory
这是仿照生物学的研究,长短期记忆结合的方案。
单一记忆模块大家都用过,这是最简单的方式,把要记住的东西(如历史的输入输出)都放到 prompt 里扔到 LLM 的 context 中。问题显而易见,历史久了,要记的东西多了容易把 context 塞爆,以及成本。
长短期记忆的方法则是:
- 短期记忆,模拟了海马体,将最近几轮的对话历史和 context,放在 prompt 中输入到 LLM
- 长期记忆,模拟了大脑皮层,将长期对话和行为历史,存储到向量数据库中,通过 RAG 激活
RecurrentGPT: Interactive Generation of (Arbitrarily) Long Text 中提到过一种针对短期记忆的更新机制:
- 传统做法,短期记忆保存在一个 session 中,session 表示为固定数量轮次的内容
- 使用 LLM 更新的短期记忆则是,基于近几轮的输入输出,使用 prompt 和 LLM,对短期记忆模块的内容进行更新,丢弃掉和最近内容无关的部分并将最新的、有用的内容提炼和加入到短期记忆模块中
因此短期记忆的信息密度是更高的,更像人类的记忆方式。
行为模块 Action
行为模块是为了帮助 LLM 完成具体的任务,比如 LLM 的计算能力较弱,那就调用 Calculator 计算并返回结果给 LLM 即可。
对 Agent 来说,行为模块分为行为和行为的目标 / 影响:
- 行为:
- 文本 / 多模态 推理 + 内容生成,可以是模型本身的能力
- 工具调用,使用外部 API 等
- 外部知识库 + RAG
- 外部数据库操作
- 调度其他小模型
- 行为目标 / 影响:
- 和人类用户交互
- 和环境交互
- 和其他 Agent 交互
- 作为中间的规划 / 反思步骤
Agent 的行为影响,会改变环境。
工具模块 Tools
会使用工具是人类的一个显著特征,我们创造、修改和利用外部物品来做出超出我们身体和认知极限的事情,为 LLM 配备外部工具也可以显著扩展模型的能力。
在 MRKL(Modular Reasoning, Knowledge and Language)架构下,LLM 扮演了路由器(router)的角色,通过查询路由找到最合适的 “专家”。这些 “专家” 可以是神经模块(Neural),例如深度学习模型,也可以是符号模块,例如数学计算器、货币转换器、天气 API 等,这些专家提供的能力,是模型权重中缺少的、模型预训练后很难更改的信息。
AI Agent 和 LLM 的区别是什么
Agent 可以感知环境,接收输入,实现自主的意图理解、规划决策、并采取改变环境的行动,调用工具,执行任务,同时具有记忆能力:
- 规划能力(Planning)
- 行动能力(Action)
- 工具使用(Tools)
- 记忆能力(Memory)
但 LLM 也同样具有以下各种能力:
- 规划能力(Planning):CoT、ToT 等等
- 行动能力(Action):LLM 可以生成内容,然后 function calling
- 工具使用(Tools):function calling
- 记忆能力(Memory):多轮会话 + Context
所以大模型和智能体到底有什么区别?
“Is it an Agent, or just an LLM?”
这个问题在 1996 年就有人问过,并给出了回答,只不过对象不是如今的 LLM:
An autonomous agent is a system situated within and a part of an environment that senses that environment and acts on it, over time, in pursuit of its own agenda and so as to effect what it senses in the future.
Is it an Agent, or just a Program?: A Taxonomy for Autonomous Agents
根据这篇论文的定义:
| Agent | LLM |
|---|---|
| 感知环境 | 仅被动接受输入 |
| 改变环境 | 仅输出回答 |
| 执行复杂任务 | 执行单一指令 |
所以看起来它们的边界非常模糊,但也可以通过它们能实际完成的任务的复杂度来进行主观区分:人的干预越少,LLM 应用的 Agentic 属性就超强,就越接近智能体。
我们离 AI Agent 有多远
从 ChatBot 到 Copilot,再到自主自驱,这是 Agentic 属性所代表的智能级别,进行推理 → 调用工具 → 自我进化。
在基础设施和硬件服务层面,Nvidia、Azure、AWS 很完善;开发框架层,Claude、Gemini、LangChain、LlamaIndex 很完善,但在软件应用层,还没有杀手级应用。
那么应用层的寒武纪什么时候到来?目前看到了以下几种观点:
- 认为正常,iPhone 07 年发布到 12 年应用爆发,经过了 5 年
- 认为大模型还不具备世界知识,它无法真正理解业务场景,比如说,你让它做一个能抗住双十一的复杂系统设计,它搞不定
- 认为大模型并不是 100% 可靠,也就是大家常说的幻觉,我们拿人来类比,一个人的知识有限,很正常,怕的是不知道自己不知道,然后胡说八道。大模型需要知道自己不知道
- 认为人类 PM 还没有找到合适的落地场景,我回看去年写的 AI 对产品的价值思考,表达过类似的意思:AI 不应该被用来掩盖产品的缺陷,如果产品本身没有一个清晰的目标或者价值主张,那么即使使用了 AI 技术,也不可能成为一个好产品
还有一点我想单独拎出来说,大家期待着 Agents 可以相互协同、自我进化:

在这个方向中,有两个问题容易被忽视。
第一个是 Agent 和外界交互实际上会很困难,理论上 Agent 可以访问外部工具,但根本没有这样的接口,没有统一的、标准化的 Agent 接口,大模型的能力会受限于其所能够访问到的外部工具的能力。为什么外部接口这么难实现,事实上,能把企业内部的 RAG 做好都很厉害了。
《LangChain 实战》作者的演讲,基于 LangChain 生态快速构建 LLM 应用
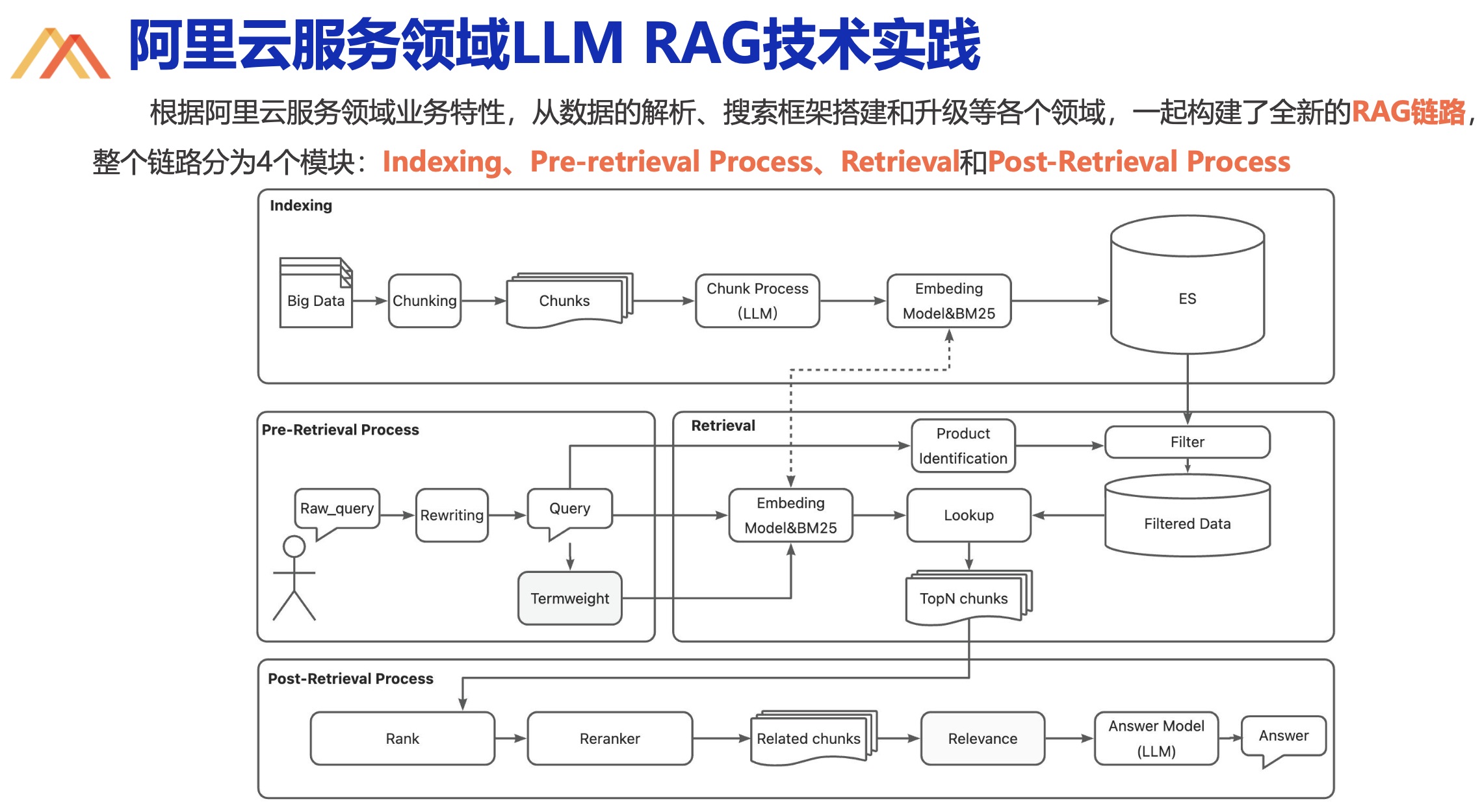
阿里云客服平台,阿里云服务领域 AIGC 基础设施的创新与实践
论文更是数不胜数,清华大学前两天刚发表了一篇 SeaKR: Self-aware Knowledge Retrieval for Adaptive Retrieval Augmented Generation。
第二个是缺少商业前景,企业这么干的动机是什么。
智能体可能产生在哪
真正的智能体有可能产生吗?还是有可能的,我们抛开技术问题、商业问题,大家在不断研究智能体的目的很纯粹,是为了超越人的智能,这个理想并不孤独,有研究单位算力的人(Nvidia),有研究大模型的人(OpenAI),有搞工程化、研究 Agent 的人,加上大语言模型的 Scaling Laws 还未失效,大家很有信心。
产生在哪,分为地区和领域。
在一次圆桌对话上,创业者们一起交流,彼此分享各自关于 go to market 的见解:
- 共识,大的市场在国外
- 国内悲观派,中国没有创业者的市场,大城市有一点机会,但从资本到政策、到端的商业模式几乎不存在,也没有新的终端(找不到增量用户,本质上还是移动互联网的存量),当年也没有像抖音这样的 “毒品”,再做一个创业产品,拿什么和一个 “毒品” 竞争,国内这么卷,从云厂商到应用端,整条产业链的利润很低
- 国内机会派,市场还是有的,可以做些特色产品,比如,日本可以做动漫、国内则可以做网文。。。(难绷)
- 国内发展派,为什么海外(市场、资本)好一些?本质上是 research 角色的缺失,很多美国公司,哪怕十几人的团队都有 researcher,或者创始人本身就是 PhD,这些人能解决关键问题,比如(马斯克)解决成本问题;国内得提高人才储备
- 不能打同质化竞争,如果产品没有差异化,仅从效率、优化角度追赶,是没有机会的,先发的优势,后发必须要用产品差异化去竞争
- 大模型的应用,在细分领域内已经开始有了超越,如 Tesla 的 FSD V12,号称代码量从 30 多万行降低到了 2000 行,背后就是神经网络的功劳;C 端落地场景里,效率 > 娱乐 > 新社交 > 新搜索 > 新电商,如吴恩达的 translation-agent 能提供比传统翻译软件更优秀的翻译结果,信达雅的水平
在去年底的极客公园创新大会中,王小川提出,AI 2.0 时代,要先 TPF(Technology-Product-Fit),因为现在是产业变化期,产业变化对人才提出的要求,第一个是懂技术,原来搞技术或者做有技术 Sense 的产品经理,都是非常好的人才,这是一个必要条件。PMF 还不好找,要等待某一个点或者突破到来,但相比传统产品,AI Native 的产品 time to value 周期会大幅缩短。
关于大模型
开源 vs 闭源
企业对大模型的核心需求是,将私域数据转化为竞争优势,并确保场景应用安全可控,大家的实现方式通常有三种
- 直接使用闭源模型,涉及到隐私安全、本地部署难的问题,但最简单
- 直接使用开源模型,自己部署,需要自己解决性能问题、达到生产要求
- 开源模型 + prompt + 知识库,难以处理复杂指令,对 prompt 的编写要求高
除了这三种,还有企业选择第四种:基于开源模型进行适配调优,这种方式能针对特定领域需求进行微调,自主选择模型结构和优化策略,灵活性很强,而且可控性高,全流程的数据、模型都不会泄漏。
背后有两点支撑。一是大模型能力的 “冰山理论”,模型的隐性能力决定了模型的上限:

其次是 Meta 开源的 Llama 在各大 Benchmark 上的表现出色:
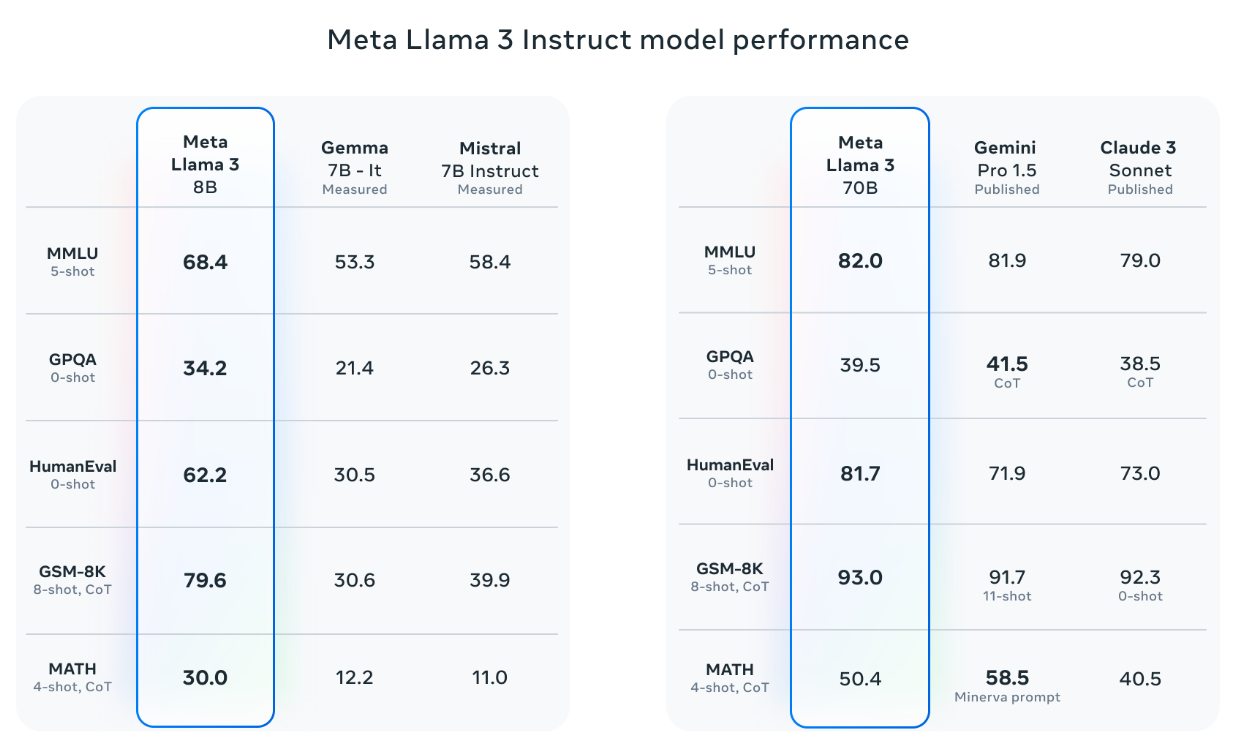
Introducing Meta Llama 3: The most capable openly available LLM to date
根据 Artificial Intelligence Index Report 2024 的数据:
- 开源 SOTA 达到闭源性能的 93%
- 已发布模型中,开源模型占比 65%
加上开源模型的迭代速度快,潜力巨大,因此很受欢迎,与此同时,落地面临的问题也是大的,体现为三大关键挑战:中文处理能力、垂域专业知识能力、企业的模型运维能力。
Workflow
现在很多 LLM 应用平台提供了 Workflow 的能力:
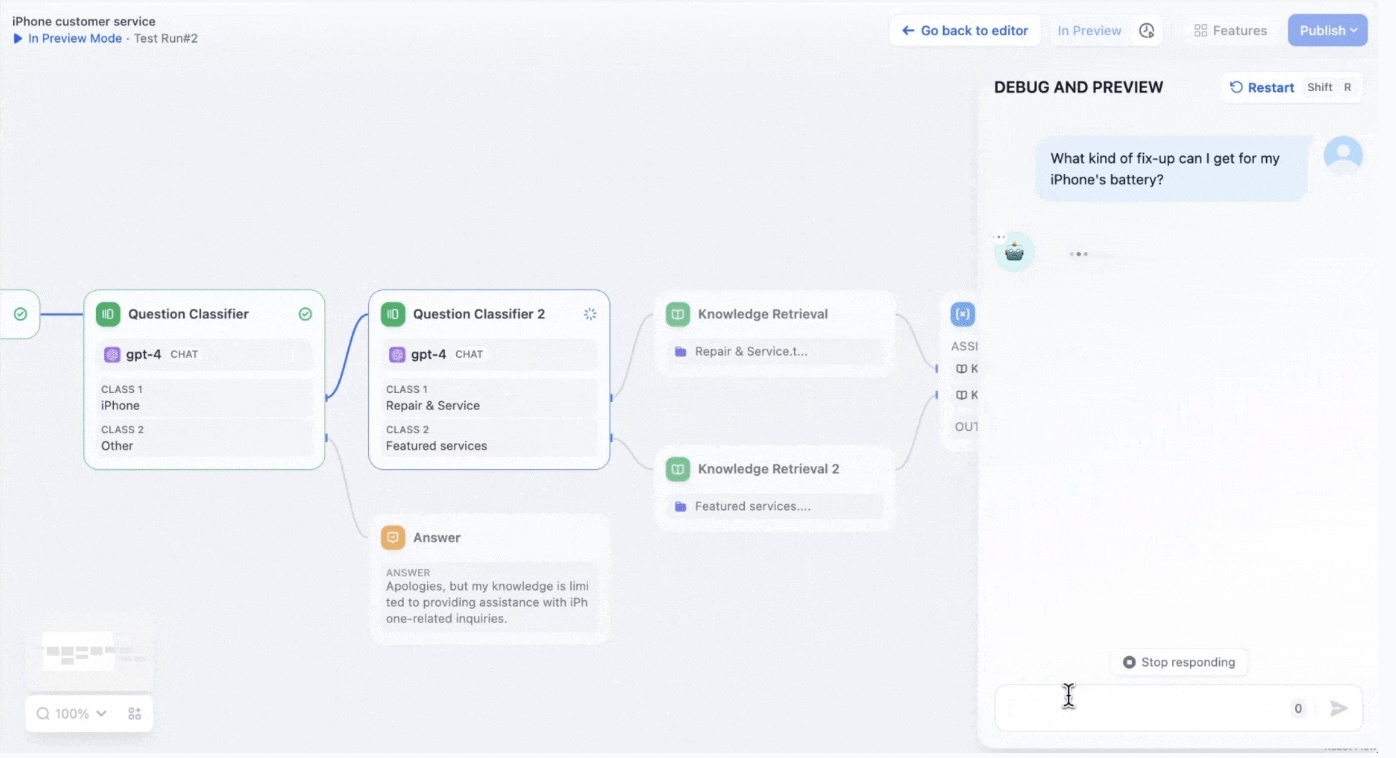
Workflow 可以理解为人类专家写的 SOP,大模型照着这份 SOP 一步步的引导用户完成业务,走的快的一些企业已经做了 Workflow + RAG 的落地实践。
经大家实践后,Workflow 被证明是一种不够好的过渡工具,主要有以下问题:
- 创建、设计节点的过程,涉及到 prompt 的编写、工具的调用,非常费时费力
- 测试成本高,每个 Workflow、节点都要 case by case 人工审核和评价
- 调优困难,节点组合到一起后 bad case 非常多
- 业务价值不高,有个销售的案例,客户在前置节点中已经充分表达出了购买意愿,Workflow 的节点还在一个接一个问问题、执行逻辑,把客户问烦了
- 节点的跳转不是线性的,如果当面节点的任务没完成,不应该进入下一个节点
Workflow 不是未来主要是因为它的 Planning 能力不行,为此有人研究了一个叫 Agent Symbolic Learning 的可自我进化的系统:

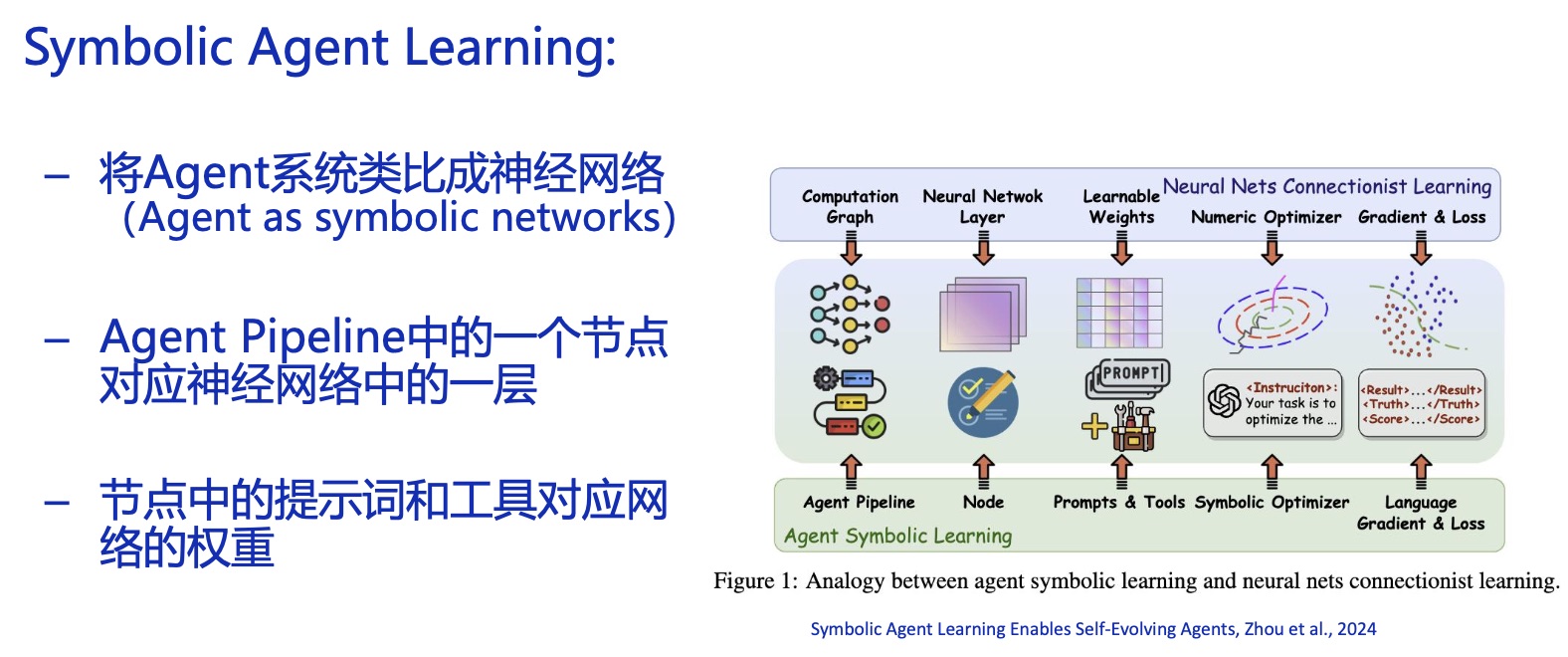
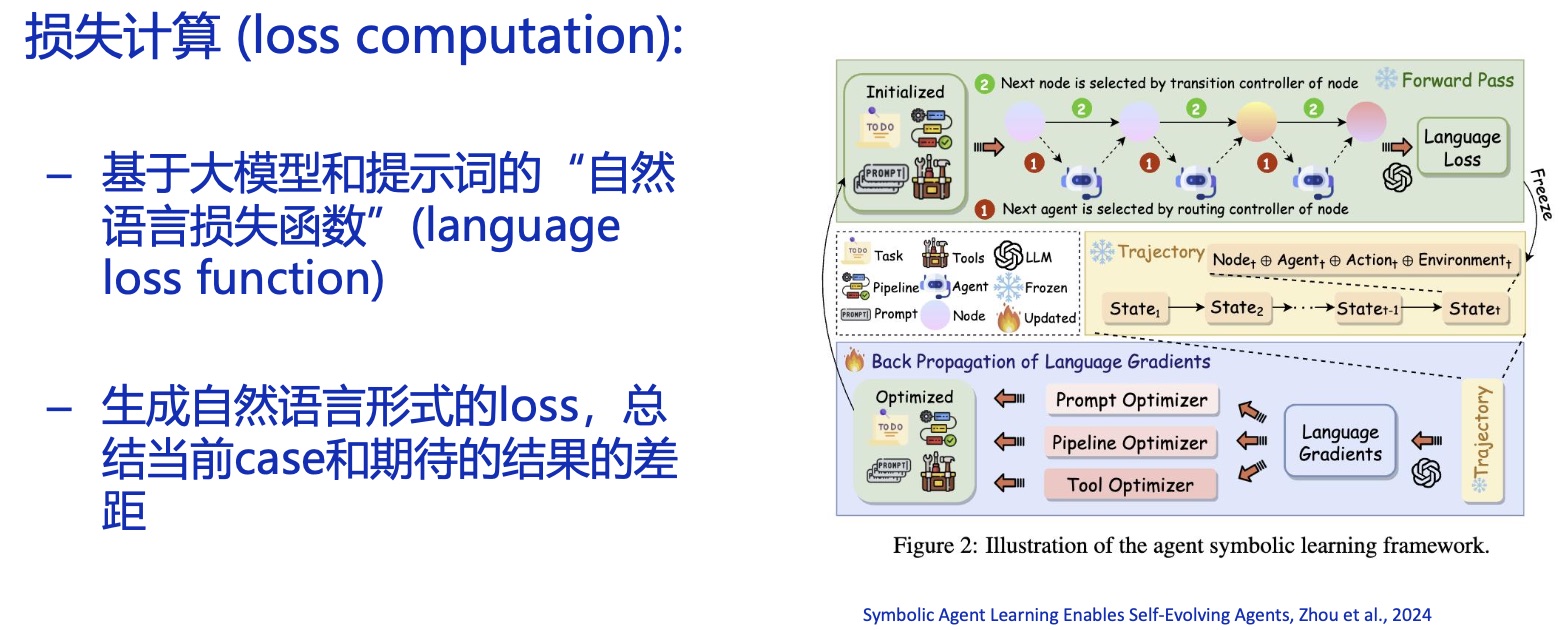
在 SOP 的基础上,根据当前节点的运行结果路由下一个节点,包括该不该进入下一个节点,以及下一个进入的是哪个节点;并且宣称学习能力比 DSPy 更厉害,DSPy 的缺点在于进化算法难以在真实场景中客观计算评分:

在自我学习能力的加持下,GPT-3.5 的结果能做到和 GPT-4 差不多,还是很厉害的。
那么对企业来说,Agent、Workflow、自训练模型、通用 LLM + prompt 都是进入 AI 的渠道,这里的选择思路是:
- 先考虑自己的场景,如果简单直接,直接 LLM
- 稍复杂的场景,对复杂任务做拆解,然后交由 SOP Workflow 或者 Agent 来解决
- 想要完全可控生成,基于开源模型调优、部署是更好的选择
作者最后以对 LPA(Life-long Personalized) 的展望结束了话题,也和其他分享嘉宾产生了梦幻般的联动。
ADI vs AGI
新加坡科研局研究员 黄佳 老师说大模型尚不具备世界知识,真要它搞一个复杂的业务场景它搞不出来:

从博士到产品经理的 陶芳波 老师说 RAG、long context 的方向是死路一条:

从学术界转战工业界的 周王春澍 老师说 LPA 才是未来:

……
从一开始的懵懵懂懂到两天的大会日程结束,回来的路上慢慢能想明白大家的意思了。
在 DeepMind 里,模型是中心化的,AGI 的背后是一个超级人类,他依靠世界知识能完成世界上绝大多数人类的工作,他是可以替代人的(Human-replacing);ADI 则代表了生物的多样性,他不是一个超级人类,没有超级大脑,他们是一群分布式的个体,Artificial Diversified Intelligence,本质上是拓展人类(Extensive)。
模型从数据中来,我们给模型提供的数据,这些可被数字化的数据,可以被记录的数据,来自我们看到了什么、听到了什么、感受到了什么,它们大多数是面向 Life Flow 产生的公开数据,比如:
- 社交媒体,微博、twitter等
- 支付记录,淘宝、拼多多、支付宝等
- 数字足迹,抖音、Keep 等
- …
但当我们想要预测一个人的行为时,这些是不够的,我们无时无刻不在思考,不断有些东西进入大脑又出去,这些 Thought Flow 的数据无法在数字化后供给 AGI,它只能给你的个人模型:大模型是世界模型,是共享的客观模型;个人的不是,是由个人的生活经历和思维模式决定的。
科幻美剧 万神殿 有一个很有意思的设定,人类的脑部能被扫描并上传到云端,从而成为新物种「Uploaded Intelligence」,它共享了全部记忆,所做出的行为和上传者如出一辙,只不过上传者要先死掉,而咱们训练 Personal Model 不用这么可怕。
如果我们用它训练自己的 Personal Model 会发生什么呢?
Second Me
你的 Personal Model 和你共享所有的记忆,你可以问他:
- 我的 MBTI 是什么?
- 我要去深圳出差了,我应该见谁?
- Q3 即将开始,我的 OGSM 要怎么写?
- 新出版的十本书,哪一本更适合我去看?
- 我应该和哪个女孩约会?
这些问题想一想都很有意思~
背后体现了模型处理个性化数据方面的能力,可以说,有没有个性化的数据,决定了 AI 的服务质量,这是 AGI 无法提供的。
Personal Model 是每个人的 Mind Model,他从了解你开始,到能帮助你干活,随着对你了解加深、记忆共享,最后会变成第二个你:Second Me。
Second Me 就像是为你定制的 App,你不需要其他 “Apps” 了,他能为你服务,也能为别人服务,如果你要去创业,你本来要去北京找沈南鹏,因为你知道他是全世界最好的投资人,但现在你去找他的 Second Me 就可以了,他的 Second Me 就是全世界最好的投资服务类 App。
Second Me 只属于你,过去我们在各种社区平台产生的数据,被平台用以商业化,平台赚走了所有的钱,我们和平台的生产关系也会因 Second Me 发生变化。樊迟 最近在烦恼如何更精准的为用户提供推荐内容,他如果有用户 Second Me 的联系方式,直接找他买就好了。
那么,回到 Second Me 诞生前,我们如何训练他呢?
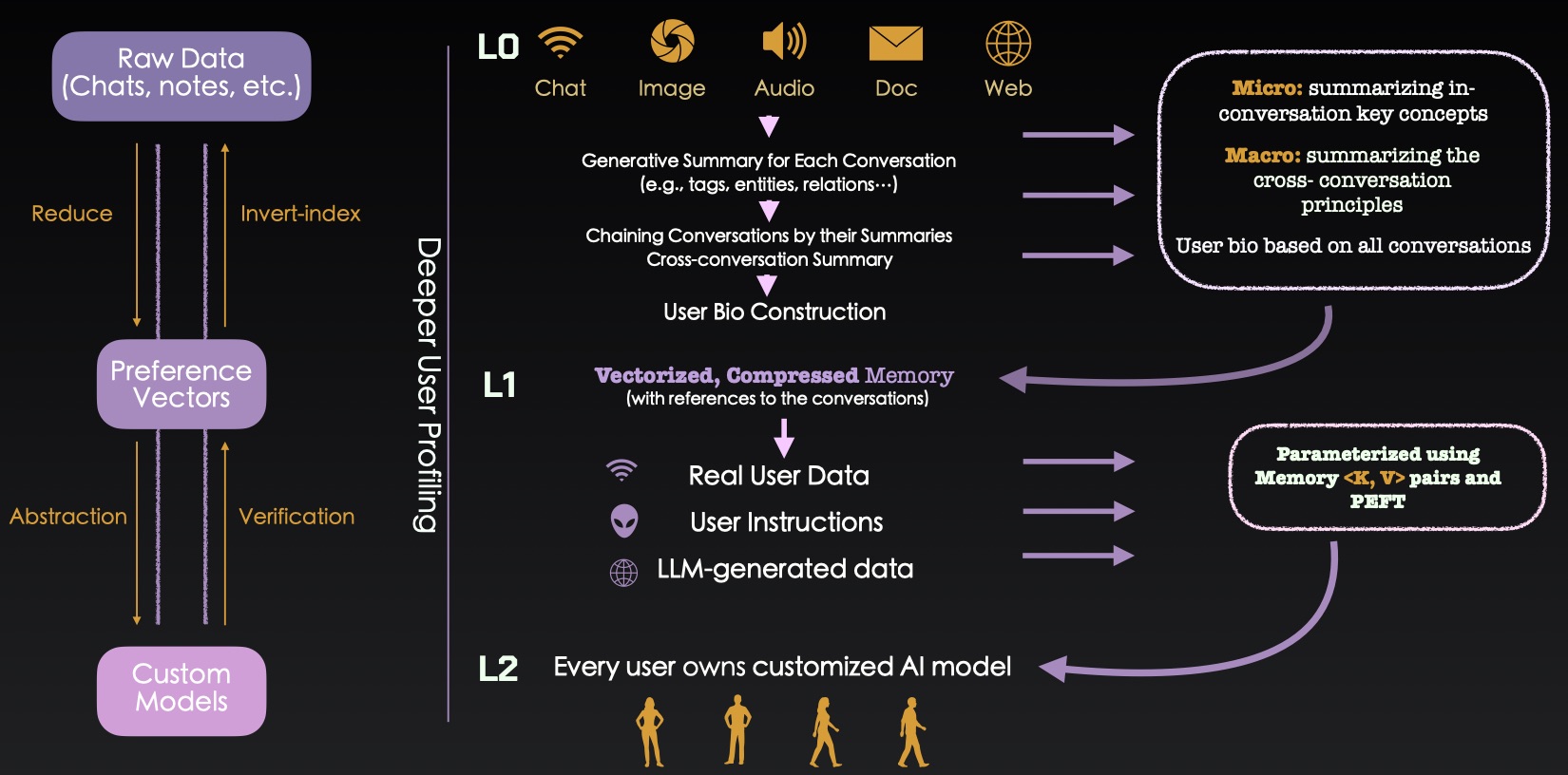
先说逻辑成立的部分:
- 多模态的数据采集方式
- Scaling Laws
- 数据全部采集下来,一个月大约一亿左右的 tokens,一年的量足够用来训练模型
- 大模型不会做 realtime
数字化的问题是目前的典型问题,我们现有的设备瓜分了我们的数据,当我们试图告知 AI 些什么的时候,这个过程往往是低效的、不标准 & 非结构化的。但逻辑成立,大家都有发送消息给微信上的自己,这些消息是什么,本质上是溢出的记忆,为什么不发给你的 AI 呢?这个过程会很自然。
因此,克服数字化问题是早晚的事,有手机就用手机,有可穿戴设备就用可穿戴设备,芯片植入技术成熟后升级到芯片植入,未来有了脑机接口后切换到脑机接口而已。
终有一天,你的 Personal Model 能回答你的个性化问题;这一天,一定会到来。
模型结构研究

大会上的一个 “异类”,数学系出身的 CEO,强行给大家科普 Transformer 是如何做逻辑推理的,介绍的很细,逻辑清晰,但明显能感觉到会场的反响不太行、热度在下降。
用非常直观的例子给大家演示了 Promot 的写法和模型指代消解能力的关系:
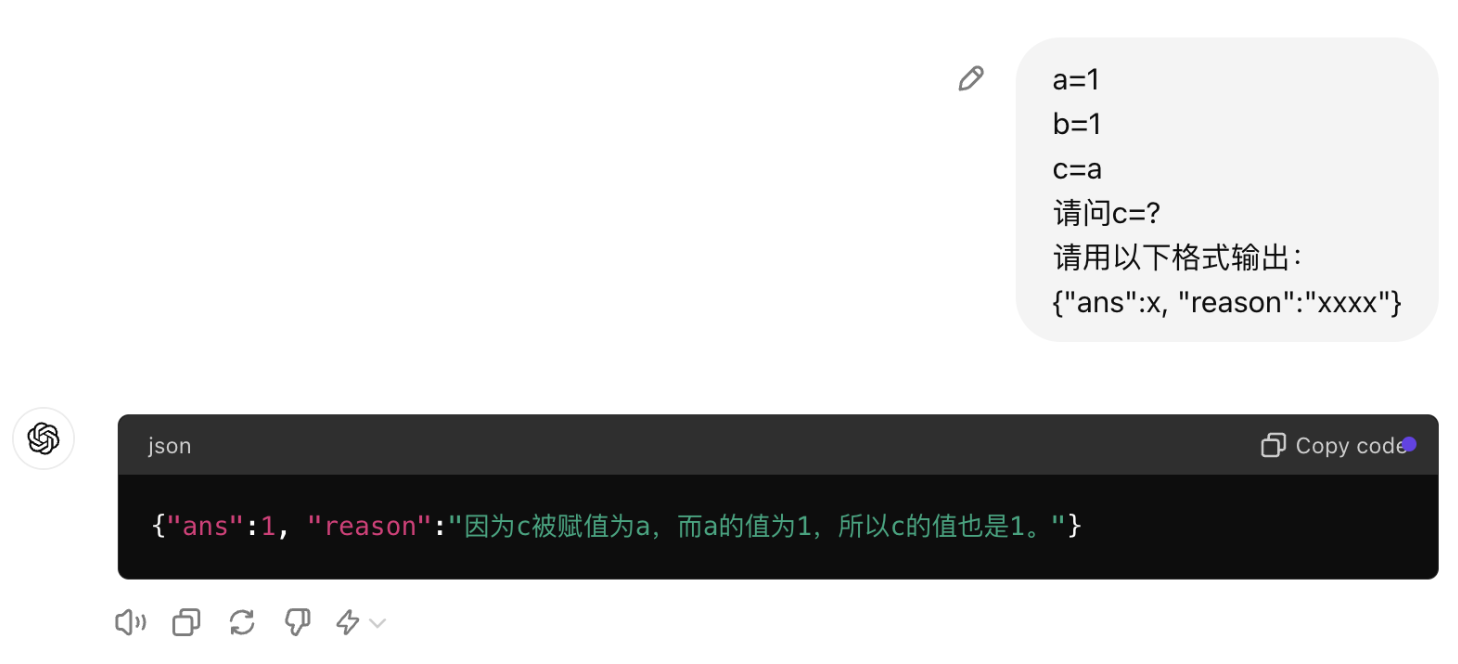
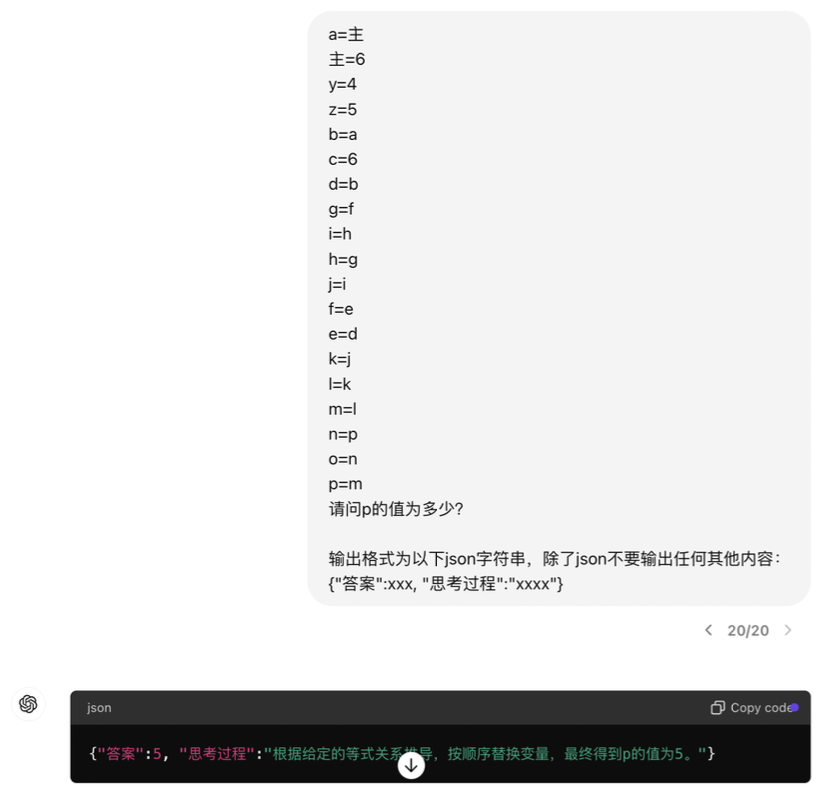
最浅显的应用点,就是:
- 控制 prompt 里代词出现的次数,每一个代词都会消解一层能力
- 指定格式输出,如 JSON 也会有同样的影响
- 将 prompt 拆解,通过多次询问能获取到一次询问得不到的答案
例子的真实意图其实是验证 GPT 模型的 Transformer 层数,然后再基于对 Transformer 结构的研究,提出了动态组合的多头注意力机制(Dynamically Composable Multi-Head Attention,DCMHA),以改进 Transformer。
最终达到了两倍的效率提升:

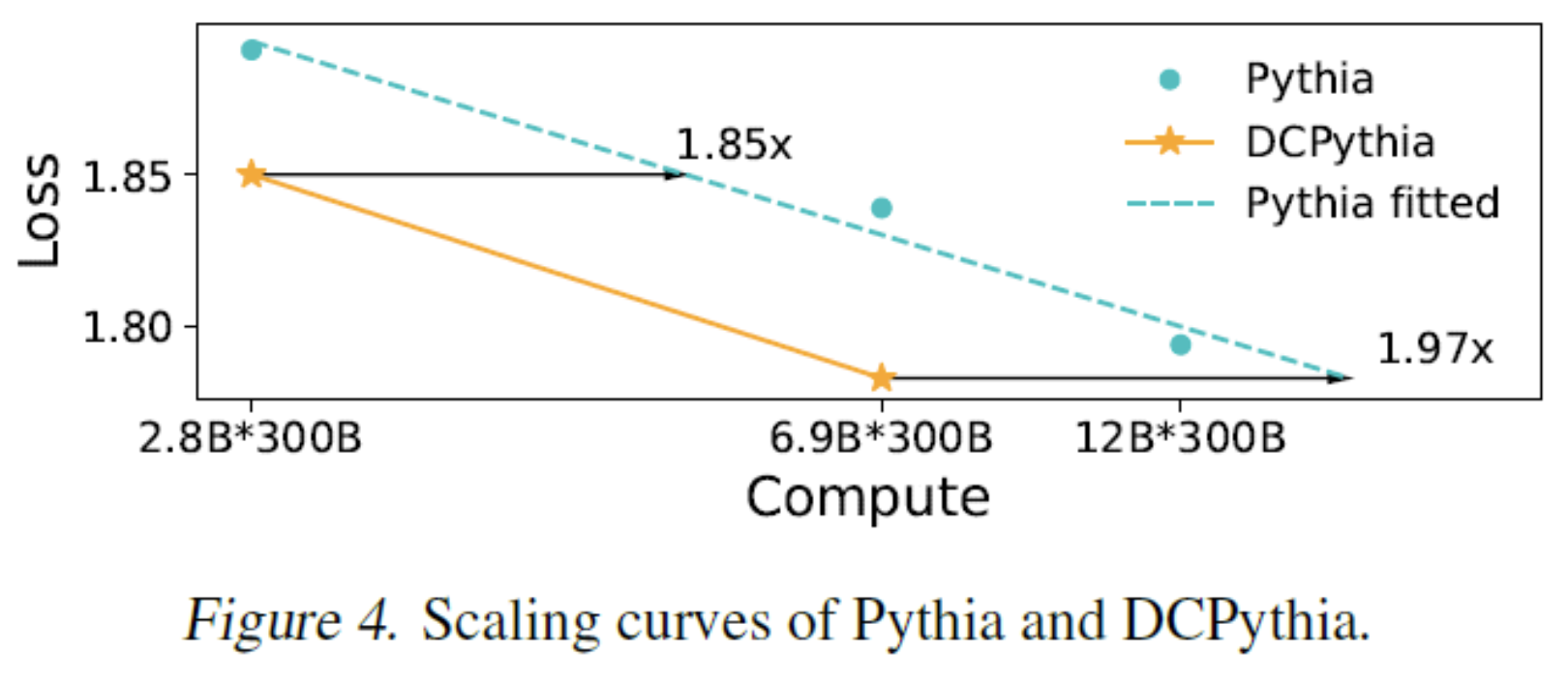
怎么理解这个提升幅度呢?
自 2017 年 Transformer 诞生以来,从改进性能算力比的角度,GLU MLP 和旋转位置编码 RoPE 是经大量实践验证普适有效且被广泛采用的为数不多的两项架构改进。
在原始 Transformer 中加入这两项改进的架构也叫 Transformer++,Llama、Mistral 等最强开源模型均采用该架构,无论 Transformer 还是 Transformer++ 架构,都可通过 DCMHA 获得显著改进。
在 1.4B 模型规模下,DCMHA 的改进幅度大于 Transformer++ 的两项改进之和,而且模型越大,效果越好,加上扩展性更好,兼容现有的 Transformer 结构,可以说,这项技术让 Transformer 的能力又跃上一个新台阶。
最后 袁行远 略带腼腆的说,DCFormer 是 ICML 今年的高分论文,在当时 100 多篇收录论文里,只有两家中国公司,一家是彩云科技,另一家是华为,言罢现场掌声雷鸣。
近年来国内这些分享大会口碑并不是很好,主要原因是两个:
- 演讲嘉宾演讲的主题大多数是讲生态、讲平台、讲架构,鲜有对具体业务问题或者具体技术点的深挖,这导致参会者无法很好的融入,很难产生高质量的互动,这些内容脱离了公司生态就没有了任何价值,复制不了
- 作为拿出来的分享内容,业界对它究竟是什么评判,是孤芳自赏的 ”好“,还是言之有物、言之有据的 ”好“,大家有自己的判断
彩云科技创业十年,这样的人,让人肃然起敬。
最后
本次大会预期不高,但收获颇丰,除了概念上的、认知上的提升,也有很多干货,比如了解到 triton 这个专门面向推理服务的 backend,据说在前后处理的编排、推理过程中都有性能提升…
以及很多小型创业公司的老板,他们的思考挺新颖的,想想也合理,现在经济环境不好、竞争激烈,真枪实弹打出来的和纸上谈兵肯定相差十万八千里,希望未来邀请更多这类老板来做分享。