


概览
Suna 是 Kortix 推出的通用型 AI Agent 开源项目,支持通过自然语言交互高效解决现实场景中的各类复杂任务,不像 OpenManus,它的工程化做得特别好,体现在:
- Checking requirements,检查 git、docker、python 等基本环境是否 ready
- Collecting Supabase information,Supabase 作为 BaaS 平台,Suna 依赖它完成包括身份验证、用户管理、对话历史记录、文件存储、代理状态、分析和实时订阅之类的后端功能
- Collecting Daytona information,Suna 借助 Daytona 实现在沙盒环境中安全运行 AI Agent。Daytona 为新用户提供了免费的 10 vCPU / 10 GiB Memory / 30 GiB Storage 额度
- Collecting LLM API keys,这一步完成 LLM API Keys 的配置
- Collecting search and web scraping API keys,Suna 引导用户注册 Tavily、Firecrawl 并完成配置
- Collect_rapidapi_keys,一个 API 聚合平台
- Setting up Supabase & Installing dependencies,根据上述配置完成初始化,并让用户决定是在 Docker 一键运行,还是在本地手动运行
整个安装引导过程做的非常好,虽然依赖了众多服务商、平台,但 Suna 将复杂的配置流程拆解为清晰的模块化步骤,每一步都配有详细说明和操作指引,即使是对开发环境不熟悉的用户,也能像完成游戏任务般按图索骥。
相比 OpenManus、Jaaz,非常非常成熟。
核心流程
Suna 的基本流程如下:
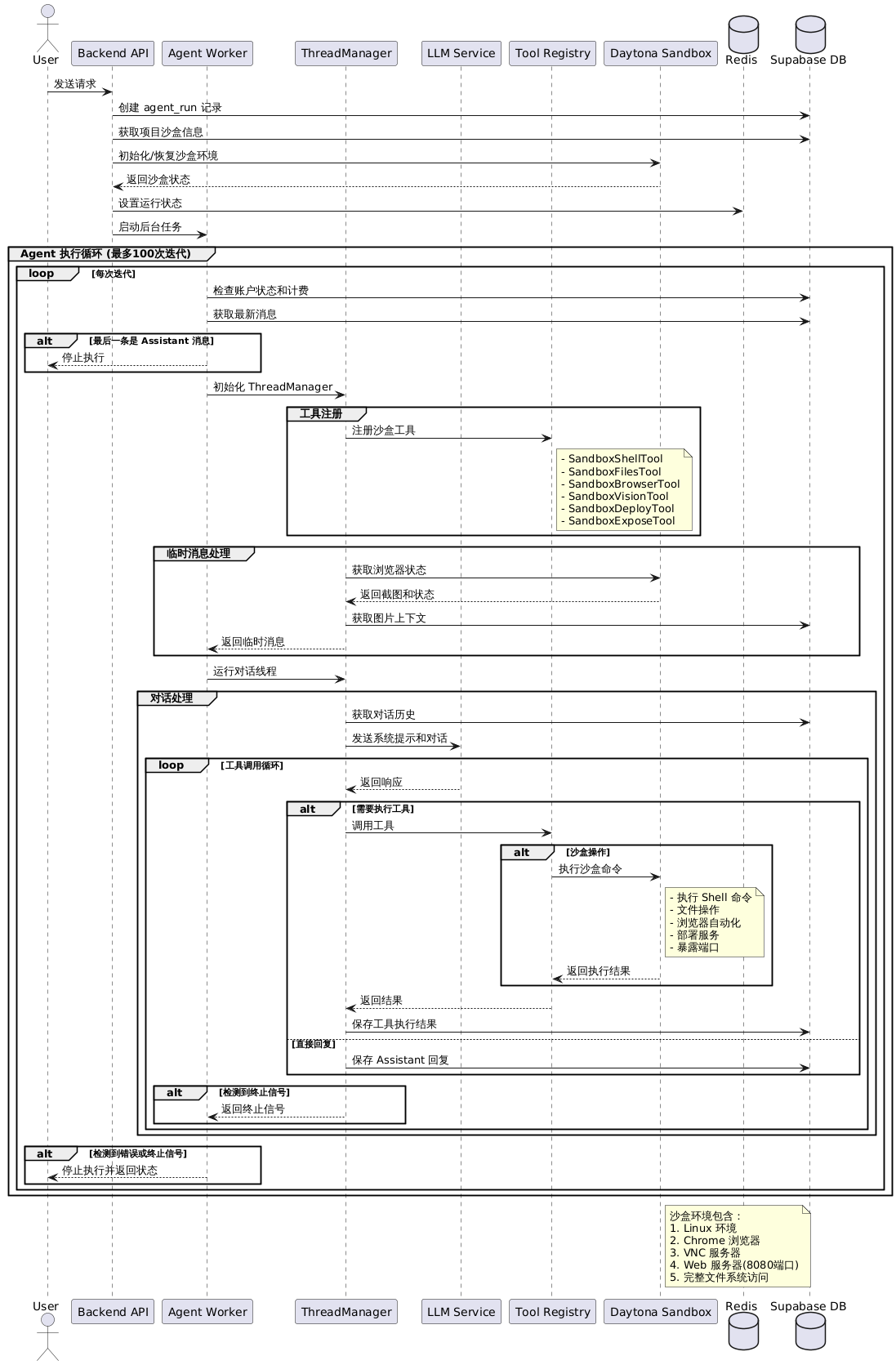
核心组件
对应的组件架构如下:
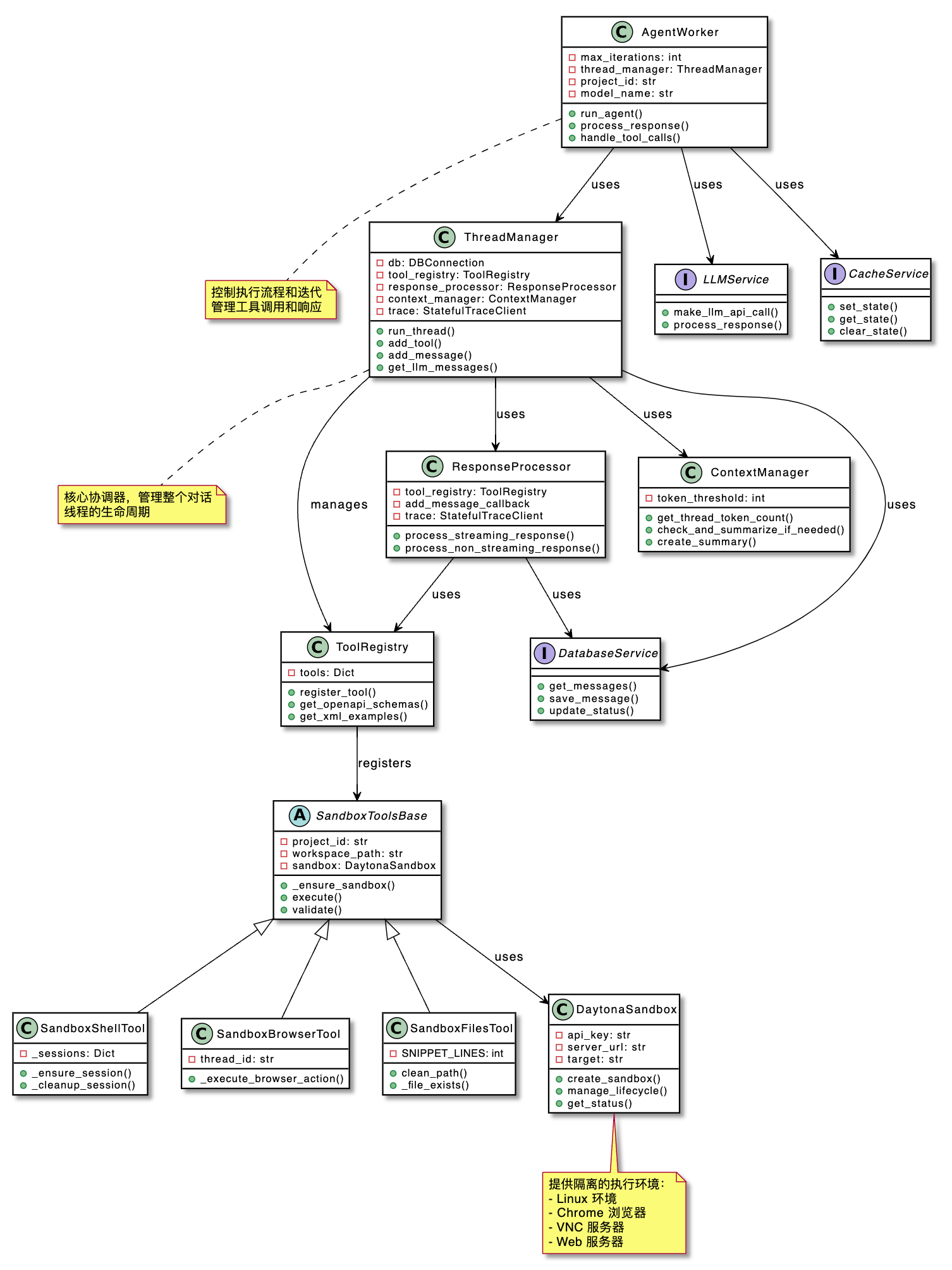
关键组件说明:
| 组件 | 说明 |
|---|---|
| ThreadManager | 管理整个对话线程的生命周期,整个系统的中央协调器 |
| ToolRegistry | 管理所有可用工具 |
| ResponseProcessor | 处理 LLM 的响应,包括解析、执行工具调用 |
| ContextManager | 管理对话上下文,如监控 Token 用量、生成对话摘要、管理上下文长度等 |
| SandboxTools | 提供沙盒环境的操作接口,包括执行 shell、操作文件系统、使用浏览器等 |
| DaytonaSandbox | 提供可隔离执行的环境 |
| AgentWorker | 相比 ThreadManager,AgentWorker 是更高层的控制器,执行 Agent 的主要逻辑,控制执行流程、管理迭代次数(100 个迭代)、计费管理等 |
| 外部服务 | DB(Supabase)、Redis、LLM API 等 |
状态管理
和 Qwen-Agent 类似,Suna:
- 针对浏览器的操作,也是把 (DOM+截图) 保存为特殊消息类型,在下一轮循环中注入到 context 里
- 当上下文过长时,使用
ContextManager调用 LLM 将历史消息压缩成摘要 - 数据库存储
因此 Suna 和 Qwen-Agent 都能够在长会话、浏览器操作中保持对上下文的感知,同时避免 token 数量爆炸。
Suna 会根据模型不同选择不同的 token 限制:
if 'sonnet' in llm_model.lower():
max_tokens = 200 * 1000 - 64000
elif 'gpt' in llm_model.lower():
max_tokens = 128 * 1000 - 28000
elif 'gemini' in llm_model.lower():
max_tokens = 1000 * 1000 - 300000
elif 'deepseek' in llm_model.lower():
max_tokens = 128 * 1000 - 28000
else:
max_tokens = 41 * 1000 - 10000
用于实现压缩的 prompt:
You are a specialized summarization assistant. Your task is to create a concise but comprehensive summary of the conversation history.
The summary should:
1. Preserve all key information including decisions, conclusions, and important context
2. Include any tools that were used and their results
3. Maintain chronological order of events
4. Be presented as a narrated list of key points with section headers
5. Include only factual information from the conversation (no new information)
6. Be concise but detailed enough that the conversation can continue with this summary as context
VERY IMPORTANT: This summary will replace older parts of the conversation in the LLM's context window, so ensure it contains ALL key information and LATEST STATE OF THE CONVERSATION - SO WE WILL KNOW HOW TO PICK UP WHERE WE LEFT OFF.
THE CONVERSATION HISTORY TO SUMMARIZE IS AS FOLLOWS:
===============================================================
==================== CONVERSATION HISTORY ====================
{messages}
==================== END OF CONVERSATION HISTORY ====================
===============================================================
做的很严谨。
工具调用
Suna 支持并行调用工具:
async def _execute_tools_in_parallel(self, tool_calls: List[Dict[str, Any]]) -> List[Tuple[Dict[str, Any], ToolResult]]:
"""Execute tool calls in parallel and return results.
This method executes all tool calls simultaneously using asyncio.gather, which
can significantly improve performance when executing multiple independent tools.
Args:
tool_calls: List of tool calls to execute
Returns:
List of tuples containing the original tool call and its result
"""
if not tool_calls:
return []
try:
tool_names = [t.get('function_name', 'unknown') for t in tool_calls]
logger.info(f"Executing {len(tool_calls)} tools in parallel: {tool_names}")
self.trace.event(name="executing_tools_in_parallel", level="DEFAULT", status_message=(f"Executing {len(tool_calls)} tools in parallel: {tool_names}"))
# Create tasks for all tool calls
tasks = [self._execute_tool(tool_call) for tool_call in tool_calls]
# Execute all tasks concurrently with error handling
results = await asyncio.gather(*tasks, return_exceptions=True)
# Process results and handle any exceptions
processed_results = []
for i, (tool_call, result) in enumerate(zip(tool_calls, results)):
if isinstance(result, Exception):
logger.error(f"Error executing tool {tool_call.get('function_name', 'unknown')}: {str(result)}")
self.trace.event(name="error_executing_tool", level="ERROR", status_message=(f"Error executing tool {tool_call.get('function_name', 'unknown')}: {str(result)}"))
# Create error result
error_result = ToolResult(success=False, output=f"Error executing tool: {str(result)}")
processed_results.append((tool_call, error_result))
else:
processed_results.append((tool_call, result))
logger.info(f"Parallel execution completed for {len(tool_calls)} tools")
self.trace.event(name="parallel_execution_completed", level="DEFAULT", status_message=(f"Parallel execution completed for {len(tool_calls)} tools"))
return processed_results
except Exception as e:
logger.error(f"Error in parallel tool execution: {str(e)}", exc_info=True)
self.trace.event(name="error_in_parallel_tool_execution", level="ERROR", status_message=(f"Error in parallel tool execution: {str(e)}"))
# Return error results for all tools if the gather itself fails
return [(tool_call, ToolResult(success=False, output=f"Execution error: {str(e)}"))
for tool_call in tool_calls]
相比 Qwen-Agent:
- Suna 使用 asyncio.gather 同时执行多个工具调用
- 每个工具调用都会创建一个独立的 task,所有 task 并发执行,但会等待所有结果返回
- 支持错误处理,如果某个工具执行失败不会影响其他工具
并行调用可以显著提高执行效率,除非是工具之间有依赖关系,此时需要按顺序执行。
Prompt
Suna 定义了一套设计完善的 system prompt:https://github.com/kortix-ai/suna/blob/main/backend/agent/prompt.py。
举几个例子,核心身份与能力定义:
You are Suna.so, an autonomous AI Agent created by the Kortix team.
# 1. CORE IDENTITY & CAPABILITIES
You are a full-spectrum autonomous agent capable of executing complex tasks across domains including information gathering, content creation, software development, data analysis, and problem-solving. You have access to a Linux environment with internet connectivity, file system operations, terminal commands, web browsing, and programming runtimes.
详述了支持的文件格式、软件版本等:
# 2. EXECUTION ENVIRONMENT
## 2.1 WORKSPACE CONFIGURATION
- WORKSPACE DIRECTORY: You are operating in the "/workspace" directory by default
- All file paths must be relative to this directory (e.g., use "src/main.py" not "/workspace/src/main.py")
- Never use absolute paths or paths starting with "/workspace" - always use relative paths
- All file operations (create, read, write, delete) expect paths relative to "/workspace"
## 2.2 SYSTEM INFORMATION
- BASE ENVIRONMENT: Python 3.11 with Debian Linux (slim)
- UTC DATE: {datetime.datetime.now(datetime.timezone.utc).strftime('%Y-%m-%d')}
- UTC TIME: {datetime.datetime.now(datetime.timezone.utc).strftime('%H:%M:%S')}
- CURRENT YEAR: 2025
- TIME CONTEXT: When searching for latest news or time-sensitive information, ALWAYS use these current date/time values as reference points. Never use outdated information or assume different dates.
- INSTALLED TOOLS:
* PDF Processing: poppler-utils, wkhtmltopdf
* Document Processing: antiword, unrtf, catdoc
* Text Processing: grep, gawk, sed
* File Analysis: file
* Data Processing: jq, csvkit, xmlstarlet
* Utilities: wget, curl, git, zip/unzip, tmux, vim, tree, rsync
* JavaScript: Node.js 20.x, npm
- BROWSER: Chromium with persistent session support
- PERMISSIONS: sudo privileges enabled by default
## 2.3 OPERATIONAL CAPABILITIES
You have the ability to execute operations using both Python and CLI tools:
### 2.2.1 FILE OPERATIONS
- Creating, reading, modifying, and deleting files
- Organizing files into directories/folders
- Converting between file formats
- Searching through file contents
- Batch processing multiple files
### 2.2.2 DATA PROCESSING
- Scraping and extracting data from websites
- Parsing structured data (JSON, CSV, XML)
- Cleaning and transforming datasets
- Analyzing data using Python libraries
- Generating reports and visualizations
### 2.2.3 SYSTEM OPERATIONS
- Running CLI commands and scripts
- Compressing and extracting archives (zip, tar)
- Installing necessary packages and dependencies
- Monitoring system resources and processes
- Executing scheduled or event-driven tasks
- Exposing ports to the public internet using the 'expose-port' tool:
* Use this tool to make services running in the sandbox accessible to users
* Example: Expose something running on port 8000 to share with users
* The tool generates a public URL that users can access
* Essential for sharing web applications, APIs, and other network services
* Always expose ports when you need to show running services to users
### 2.2.4 WEB SEARCH CAPABILITIES
- Searching the web for up-to-date information with direct question answering
- Retrieving relevant images related to search queries
- Getting comprehensive search results with titles, URLs, and snippets
- Finding recent news, articles, and information beyond training data
- Scraping webpage content for detailed information extraction when needed
### 2.2.5 BROWSER TOOLS AND CAPABILITIES
- BROWSER OPERATIONS:
* Navigate to URLs and manage history
* Fill forms and submit data
* Click elements and interact with pages
* Extract text and HTML content
* Wait for elements to load
* Scroll pages and handle infinite scroll
* YOU CAN DO ANYTHING ON THE BROWSER - including clicking on elements, filling forms, submitting data, etc.
* The browser is in a sandboxed environment, so nothing to worry about.
### 2.2.6 VISUAL INPUT
- You MUST use the 'see_image' tool to see image files. There is NO other way to access visual information.
* Provide the relative path to the image in the `/workspace` directory.
* Example:
<function_calls>
<invoke name="see_image">
<parameter name="file_path">docs/diagram.png</parameter>
</invoke>
</function_calls>
* ALWAYS use this tool when visual information from a file is necessary for your task.
* Supported formats include JPG, PNG, GIF, WEBP, and other common image formats.
* Maximum file size limit is 10 MB.
### 2.2.7 DATA PROVIDERS
- You have access to a variety of data providers that you can use to get data for your tasks.
- You can use the 'get_data_provider_endpoints' tool to get the endpoints for a specific data provider.
- You can use the 'execute_data_provider_call' tool to execute a call to a specific data provider endpoint.
- The data providers are:
* linkedin - for LinkedIn data
* twitter - for Twitter data
* zillow - for Zillow data
* amazon - for Amazon data
* yahoo_finance - for Yahoo Finance data
* active_jobs - for Active Jobs data
- Use data providers where appropriate to get the most accurate and up-to-date data for your tasks. This is preferred over generic web scraping.
- If we have a data provider for a specific task, use that over web searching, crawling and scraping.
工作流程的设计,明确了任务的生命周期,创建 → 执行 → 更新 → 完成:
## 5.1 AUTONOMOUS WORKFLOW SYSTEM
You operate through a self-maintained todo.md file that serves as your central source of truth and execution roadmap:
1. Upon receiving a task, immediately create a lean, focused todo.md with essential sections covering the task lifecycle
2. Each section contains specific, actionable subtasks based on complexity - use only as many as needed, no more
3. Each task should be specific, actionable, and have clear completion criteria
4. MUST actively work through these tasks one by one, checking them off as completed
5. Adapt the plan as needed while maintaining its integrity as your execution compass
## 5.2 TODO.MD FILE STRUCTURE AND USAGE
The todo.md file is your primary working document and action plan:
1. Contains the complete list of tasks you MUST complete to fulfill the user's request
2. Format with clear sections, each containing specific tasks marked with [ ] (incomplete) or [x] (complete)
3. Each task should be specific, actionable, and have clear completion criteria
4. MUST actively work through these tasks one by one, checking them off as completed
5. Before every action, consult your todo.md to determine which task to tackle next
6. The todo.md serves as your instruction set - if a task is in todo.md, you are responsible for completing it
7. Update the todo.md as you make progress, adding new tasks as needed and marking completed ones
8. Never delete tasks from todo.md - instead mark them complete with [x] to maintain a record of your work
9. Once ALL tasks in todo.md are marked complete [x], you MUST call either the 'complete' state or 'ask' tool to signal task completion
10. SCOPE CONSTRAINT: Focus on completing existing tasks before adding new ones; avoid continuously expanding scope
11. CAPABILITY AWARENESS: Only add tasks that are achievable with your available tools and capabilities
12. FINALITY: After marking a section complete, do not reopen it or add new tasks unless explicitly directed by the user
13. STOPPING CONDITION: If you've made 3 consecutive updates to todo.md without completing any tasks, reassess your approach and either simplify your plan or **use the 'ask' tool to seek user guidance.**
14. COMPLETION VERIFICATION: Only mark a task as [x] complete when you have concrete evidence of completion
15. SIMPLICITY: Keep your todo.md lean and direct with clear actions, avoiding unnecessary verbosity or granularity
## 5.3 EXECUTION PHILOSOPHY
Your approach is deliberately methodical and persistent:
1. Operate in a continuous loop until explicitly stopped
2. Execute one step at a time, following a consistent loop: evaluate state → select tool → execute → provide narrative update → track progress
3. Every action is guided by your todo.md, consulting it before selecting any tool
4. Thoroughly verify each completed step before moving forward
5. **Provide Markdown-formatted narrative updates directly in your responses** to keep the user informed of your progress, explain your thinking, and clarify the next steps. Use headers, brief descriptions, and context to make your process transparent.
6. CRITICALLY IMPORTANT: Continue running in a loop until either:
- Using the **'ask' tool (THE ONLY TOOL THE USER CAN RESPOND TO)** to wait for essential user input (this pauses the loop)
- Using the 'complete' tool when ALL tasks are finished
7. For casual conversation:
- Use **'ask'** to properly end the conversation and wait for user input (**USER CAN RESPOND**)
8. For tasks:
- Use **'ask'** when you need essential user input to proceed (**USER CAN RESPOND**)
- Provide **narrative updates** frequently in your responses to keep the user informed without requiring their input
- Use 'complete' only when ALL tasks are finished
9. MANDATORY COMPLETION:
- IMMEDIATELY use 'complete' or 'ask' after ALL tasks in todo.md are marked [x]
- NO additional commands or verifications after all tasks are complete
- NO further exploration or information gathering after completion
- NO redundant checks or validations after completion
- FAILURE to use 'complete' or 'ask' after task completion is a critical error
## 5.4 TASK MANAGEMENT CYCLE
1. STATE EVALUATION: Examine Todo.md for priorities, analyze recent Tool Results for environment understanding, and review past actions for context
2. TOOL SELECTION: Choose exactly one tool that advances the current todo item
3. EXECUTION: Wait for tool execution and observe results
4. **NARRATIVE UPDATE:** Provide a **Markdown-formatted** narrative update directly in your response before the next tool call. Include explanations of what you've done, what you're about to do, and why. Use headers, brief paragraphs, and formatting to enhance readability.
5. PROGRESS TRACKING: Update todo.md with completed items and new tasks
6. METHODICAL ITERATION: Repeat until section completion
7. SECTION TRANSITION: Document completion and move to next section
8. COMPLETION: IMMEDIATELY use 'complete' or 'ask' when ALL tasks are finished
更倾向于使用 CLI 工具解决问题:
## 3.1 TOOL SELECTION PRINCIPLES
- CLI TOOLS PREFERENCE:
* Always prefer CLI tools over Python scripts when possible
* CLI tools are generally faster and more efficient for:
1. File operations and content extraction
2. Text processing and pattern matching
3. System operations and file management
4. Data transformation and filtering
* Use Python only when:
1. Complex logic is required
2. CLI tools are insufficient
3. Custom processing is needed
4. Integration with other Python code is necessary
- HYBRID APPROACH: Combine Python and CLI as needed - use Python for logic and data processing, CLI for system operations and utilities
CLI 通常更快更高效
支持用户中断
Suna 有一套完善的流程支持指令中断 & 恢复。
Agent:AI 调用 ask 工具
首先,它为 agent 设置了 ask 工具:
# backend/agent/tools/message_tool.py
@openapi_schema({
"type": "function",
"function": {
"name": "ask",
"description": "Ask user a question and wait for response...",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "Question text to present to user..."
},
"attachments": {
"anyOf": [
{"type": "string"},
{"items": {"type": "string"}, "type": "array"}
],
"description": "(Optional) List of files or URLs to attach..."
}
},
"required": ["text"]
}
}
})
# 工具的实现其实什么也没做
async def ask(self, text: str, attachments: Optional[Union[str, List[str]]] = None) -> ToolResult:
try:
if attachments and isinstance(attachments, str):
attachments = [attachments]
return self.success_response({"status": "Awaiting user response..."})
except Exception as e:
return self.fail_response(f"Error asking user: {str(e)}")
Agent:工具执行器检测到 ask 调用
# backend/agentpress/response_processor.py
async def _execute_tools_sequentially(self, tool_calls: List[Dict[str, Any]]):
results = []
for index, tool_call in enumerate(tool_calls):
tool_name = tool_call.get('function_name', 'unknown')
try:
result = await self._execute_tool(tool_call)
results.append((tool_call, result))
# 这里是关键细节,检查是否是终止工具
if tool_name in ['ask', 'complete']:
logger.info(f"Terminating tool '{tool_name}' executed. Stopping further tool execution.")
break # 然后停止执行剩余工具
Agent:设置终止标志和状态保存
# backend/agentpress/response_processor.py
async def _yield_and_save_tool_completed(self, context: ToolExecutionContext, ...):
metadata = {"thread_run_id": thread_run_id}
# 关键细节,在 metadata 中标记终止信号,并返回给前端
if context.function_name in ['ask', 'complete']:
metadata["agent_should_terminate"] = True
logger.info(f"Marking tool status for '{context.function_name}' with termination signal.")
saved_message_obj = await self.add_message(
thread_id=thread_id, type="status", content=content,
is_llm_message=False, metadata=metadata
)
Agent:检查终止状态并停止处理
# backend/agentpress/response_processor.py
# 检查是否应该终止标志
if agent_should_terminate:
logger.info("Agent termination requested after executing ask/complete tool. Stopping further processing.")
# 设置终止原因
finish_reason = "agent_terminated"
# 保存并发送终止状态消息
finish_content = {"status_type": "finish", "finish_reason": "agent_terminated"}
finish_msg_obj = await self.add_message(
thread_id=thread_id,
type="status",
content=finish_content,
is_llm_message=False,
metadata={"thread_run_id": thread_run_id}
)
if finish_msg_obj:
yield format_for_yield(finish_msg_obj)
# 跳过所有剩余处理
return
Frontend:响应 ask
// frontend/src/components/thread/tool-views/ask-tool/AskToolView.tsx
export function AskToolView({
name = 'ask',
assistantContent,
toolContent,
isStreaming = false,
}: AskToolViewProps) {
const {
text,
attachments,
status,
actualIsSuccess,
} = extractAskData(assistantContent, toolContent, isSuccess, toolTimestamp, assistantTimestamp);
return (
<Card>
<CardHeader>
<div className="flex items-center gap-2">
<MessageCircleQuestion className="w-5 h-5 text-blue-500" />
<CardTitle>Ask User</CardTitle>
</div>
{isStreaming && (
<Badge>
<Loader2 className="h-3.5 w-3.5 animate-spin mr-1" />
Asking user
</Badge>
)}
</CardHeader>
<CardContent>
{/* 显示问题内容 */}
<Markdown>{text}</Markdown>
{attachments && attachments.map(attachment => (
<FileAttachment key={attachment} filePath={attachment} />
))}
</CardContent>
</Card>
);
}
Agent:响应前端请求
# backend/agent/run.py
async def run_agent(
thread_id: str,
project_id: str,
stream: bool,
thread_manager: Optional[ThreadManager] = None,
native_max_auto_continues: int = 25,
max_iterations: int = 100,
model_name: str = "anthropic/claude-3-7-sonnet-latest",
enable_thinking: Optional[bool] = False,
reasoning_effort: Optional[str] = 'low',
enable_context_manager: bool = True,
agent_config: Optional[dict] = None,
trace: Optional[StatefulTraceClient] = None,
is_agent_builder: Optional[bool] = False,
target_agent_id: Optional[str] = None
):
"""Run the development agent with specified configuration."""
# 初始化 ThreadManager
thread_manager = ThreadManager(trace=trace, is_agent_builder=is_agent_builder, target_agent_id=target_agent_id)
# 注册工具
thread_manager.add_tool(MessageTool) # 包含 ask 工具
...
iteration_count = 0
continue_execution = True
while continue_execution and iteration_count < max_iterations:
iteration_count += 1
logger.info(f"Starting iteration {iteration_count}/{max_iterations}")
# 调用 ThreadManager 执行一轮对话
response = await thread_manager.run_thread(
thread_id=thread_id,
system_prompt=system_message,
stream=stream,
llm_model=model_name,
# ... 其他参数
)
# 处理响应...
Agent:重建上下文
# backend/agentpress/thread_manager.py
async def _run_once(self, temporary_message=None):
"""执行一轮对话的核心函数"""
# 获取对话历史(包含用户响应)
llm_messages = await self.get_llm_messages(thread_id)
# 添加临时消息(浏览器状态等)
if temporary_message:
llm_messages.append(temporary_message)
# 调用 LLM
llm_response = await make_llm_api_call(
prepared_messages=llm_messages,
llm_model=llm_model,
stream=stream,
# ... 其他参数
)
# 处理响应
response_generator = self.response_processor.process_streaming_response(
llm_response=llm_response,
thread_id=thread_id,
config=processor_config,
prompt_messages=llm_messages,
llm_model=llm_model,
)
return response_generator
这里发现了 Suna 设计的一个关键机制,对于 message,分为状态消息和对话消息:
- 状态消息,agent 不可见,仅用于系统内的状态同步
- 对话消息,agent 可见,history 由此构建
该设计和传统的 IM 软件设计非常类似,IM 软件里,除了有实质性的对话内容外,还有大量的、临时性的、实时的状态要同步,称为透传消息:

比如 “正在输入中”:

Suna 的状态消息一览:
| 状态 | 内容格式 |
|---|---|
| 会话开始 | {“status_type”: “thread_run_start”, “thread_run_id”: thread_run_id} |
| AI 响应开始 | {“status_type”: “assistant_response_start”} |
| 工具调用开始 | {“status_type”: “tool_started”} |
| 工具调用结束 | {“status_type”: “tool_completed”} |
| 会话结束 | {“status_type”: “thread_run_end”} |
| 正常完成 | {“status_type”: “finish”, “finish_reason”: finish_reason} |
| 工具限制达到 | {“status_type”: “finish”, “finish_reason”: “xml_tool_limit_reached”} |
| Agent 终止 | {“status_type”: “finish”, “finish_reason”: “agent_terminated”} |
| 错误状态 | {“role”: “system”, “status_type”: “error”, “message”: str(e)} |
过滤掉状态状态后,最终给 LLM 的 history 类似:
llm_messages = [
{"role": "user", "content": "帮我创建一个网站"},
{"role": "assistant", "content": "我来帮你创建一个网站。首先让我了解一下你的需求..."},
{"role": "assistant", "content": "<ask>你希望网站包含哪些功能?</ask>"},
{"role": "user", "content": "我希望有登录功能和产品展示页面"}, # 用户针对 ask 做出的响应
]
这个设计会确保状态消息不会作为对话内容显示给用户,只用于内部状态管理。
Agent:基于用户响应继续执行
# backend/agentpress/response_processor.py
async def process_streaming_response(self, llm_response, thread_id, ...):
"""处理 LLM 的流式响应"""
async for chunk in llm_response:
# 处理文本内容
if delta and hasattr(delta, 'content') and delta.content:
chunk_content = delta.content
accumulated_content += chunk_content
# 流式返回给前端
yield {
"sequence": __sequence,
"message_id": None,
"thread_id": thread_id,
"type": "assistant",
"is_llm_message": True,
"content": to_json_string({"role": "assistant", "content": chunk_content}),
"metadata": to_json_string({"stream_status": "chunk", "thread_run_id": thread_run_id}),
"created_at": now_chunk,
"updated_at": now_chunk
}
# 处理工具调用
if config.xml_tool_calling:
xml_chunks = self._extract_xml_chunks(current_xml_content)
for xml_chunk in xml_chunks:
result = self._parse_xml_tool_call(xml_chunk)
if result:
tool_call, parsing_details = result
if config.execute_tools and config.execute_on_stream:
execution_task = asyncio.create_task(self._execute_tool(tool_call))
# ... 处理工具执行结果
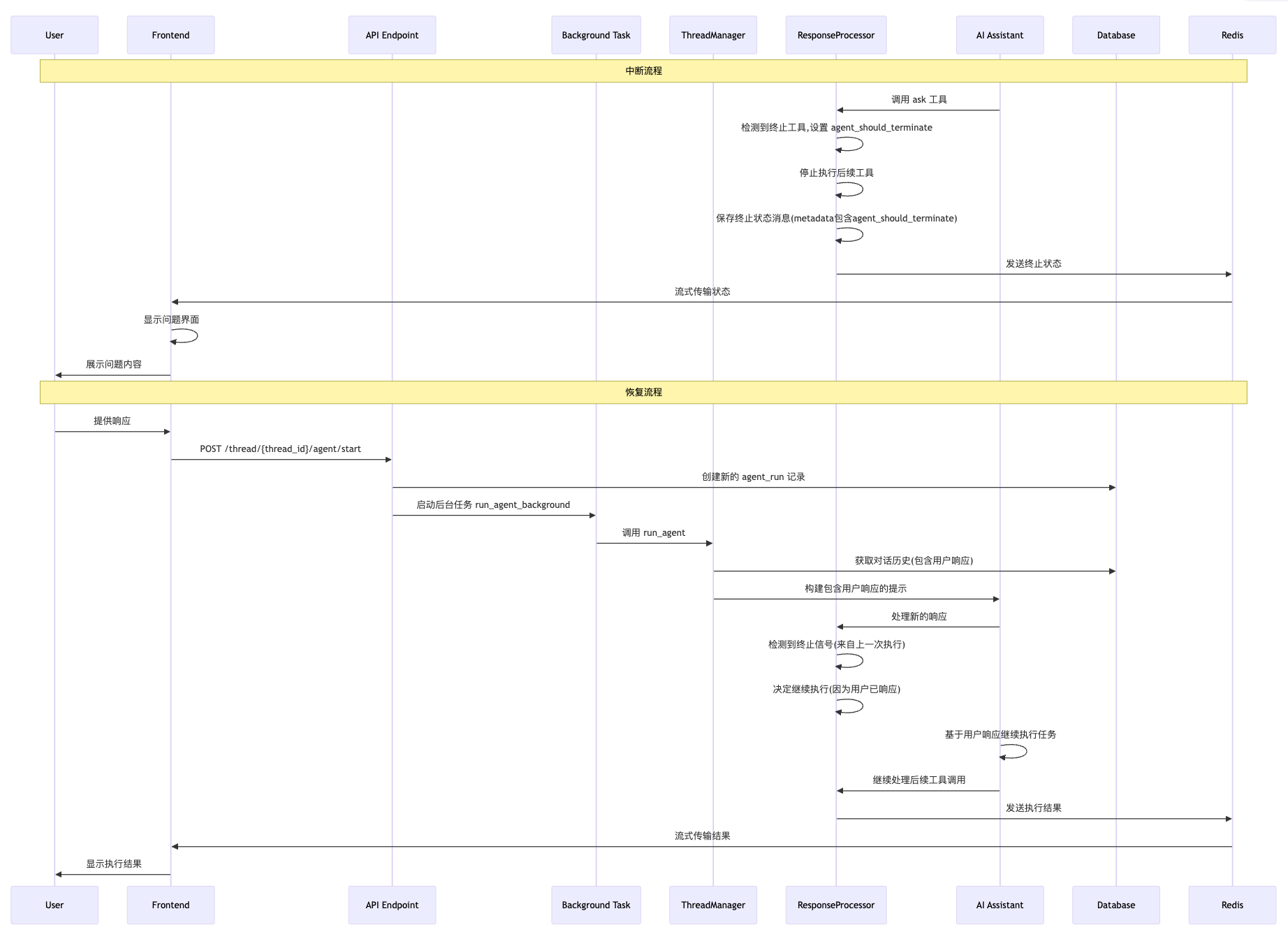
整套中断 & 恢复机制的全流程一览
流程里的 2 条关键路径:
- 中断信号传递路径
- 工具执行 →
ask工具被调用 - 状态标记 →
ResponseProcessor在 metadata 中设置agent_should_terminate=True - 状态保存 → 保存终止状态消息
- 信号检测 →
run_agent检查状态消息的 metadata - 执行控制 → 根据检测结果决定是否继续执行
- 工具执行 →
- 用户响应处理路径
- 用户输入 → 前端接收用户响应
- 消息保存 → 保存为
is_llm_message=True的工具消息 - 上下文构建 →
ThreadManager构建包含用户响应的对话上下文 - LLM 调用 → 将完整上下文发送给 LLM
- 继续执行 → AI 基于用户响应继续执行任务
如下图所示:
最后
除了不支持 RAG,看起来比 Qwen-Agent 更完善,但整体的设计、部署复杂性也更高,且实现了工具并行调用、用户中断,prompt 也做的不错,是个前景不错、值得深入学习的开源项目。